모델을 선택한 다음 해야할 일은 모델의 hyperparameter를 정하는 hyperparameter tuning 과정입니다.
Parameter를 학습시킬 때 train data를 사용하여 score를 비교하고 가장 높은 score를 보여준 parameter를 선택하였습니다. 적절한 hyperparameter를 찾을 땐 overfitting을 막기 위해 train data와 분리된 validation data를 사용하는데요. Validation data를 나누고 tuning 하는 방법을 크게 2가지로 구분할 수 있습니다.
1. Slow <Train - Predict - Score>
Deep learning과 같이 많은 양의 데이터를 다루거나 학습시키고 예측하여 score를 계산하는 시간이 오래 걸리는 경우, 처음 data를 나눌 때 서로 격리된 train / validation / test data 로 나눕니다.
Train data와 마찬가지로 validation data에서 발생하는 cost가 test data에서 발생하는 cost와 유사할 것이다 라는 전제하에 validation data에서 가장 좋은 성능을 보여주는 hyperparameter를 선택할 수 있습니다.
2. Fast <Train - Predict - Score>
또다른 방법은 먼저 validation data를 정해놓지 않고 데이터를 train / test data로 나눕니다. Train data를 동일한 크기를 가진 k개의 fold로 분할한 다음, 각각의 fold를 validation data로, 그 외의 (k-1)개의 folds를 train data로 하는 데이터셋 k개를 생각해볼 수 있습니다. 그리고 동일한 hyperparameter를 가진 모델을 k개 만들어 각 데이터셋에 대해서 학습한 결과 score의 평균을 구하고 이 과정을 각 hyperparameter 마다 반복하여 비교할 수 있습니다. 이러한 방법을 k-fold cross validation이라고 합니다.
Cross validation은 하나의 hyperparameter를 평가하기 위해 서로 다른 train / validation data에 대한 k개의 모델을 학습시키고 그 평균값으로 평가하기 때문에 hyperparameter의 일반화 성능에 대한 신뢰성이 높을 뿐만 아니라, validation data가 고정되어 있지 않아 train data의 효율성을 극대화하는 방법으로 자주 사용되는 방법입니다.
sklearn에서 기본적인 estimator를 모델로 사용한다면 여러가지 종류의 cross validation 함수를 사용할 수 있습니다.
※ n_jobs=-1 option을 사용하여 CPU 병렬화를 최대화시키도록 합시다!
1) cross_val_score()
각각의 validation fold에 대한 score를 반환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sklearn.model_selection import cross_val_score
reg_scores = cross_val_score(reg, X_train, y_train, scoring='neg_mean_squared_error', cv=10) # Regressor
clf_scores = cross_val_score(clf, X_train, y_train, scoring='accuracy', cv=10, n_jobs=-1) # Classifier
def display_scores(scores, type=None):
if type == 'nmse':
scores = np.sqrt(-scores)
print('Scores:', scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(reg_scores, 'nmse')
display_scores(clf_scores)
2) cross_val_predict()
각각의 validation fold에 대한 예측값을 반환합니다. (unseen data에 대한 예측값이기 때문에 clean predict라고도 부릅니다)
1
2
3
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(clf, X_train, y_train, cv=5, n_jobs=-1)
3) GridSearchCV()
Grid search를 하여 hyperparameter tuning할 수 있는 class입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error', return_train_score=True, n_jobs=-1)
grid_search.fit(housing_prepared, housing_labels)
grid_search.best_params_
grid_search.best_estimator_
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres['mean_test_score'], cvres['params']):
print(np.sqrt(-mean_score), params)
pd.DataFrame(grid_search.cv_results_)
feature_importances = grid_search.best_estimator_.feature_importances_ # feature의 중요도를 알 수 있습니다
4) RandomizedSearchCV()
Random search를 하여 hyperparameter tuning할 수 있는 class입니다. (scipy.stats의 여러가지 확률분포들을 사용할 수 있습니다)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from sklearn.model_selection import RandomSearchCV
from scipy.stats import randint
param_dist = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8)
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_dist, n_iter=10, cv=5,
scoring='neg_mean_squared_error', return_train_score=True, random_state=42, n_jobs=-1)
rnd_search.fit(housing_prepared, housing_labels)
rnd_search.best_params_
rnd_search.best_estimator_
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres['mean_test_score'], cvres['params']):
print(np.sqrt(-mean_score), params)
pd.DataFrame(grid_search.cv_results_)
5) validation_curve()
train_score와 validation_score를 같이 반환하는 함수입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from sklearn.model_selection import validation_curve
def plot_validation_curve(model, param_name, param_rage):
train_scores, val_scores = validation_curve(model, X_train_1000, y_train_1000, param_name=param_name, param_range=param_range, cv=3, scoring='neg_mean_squared_error', n_jobs=-1)
train_scores_mean = np.mean(-train_scores, axis=-1)
train_scores_std = np.std(train_scores, axis=-1)
val_scores_mean = np.mean(-val_scores, axis=-1)
val_scores_std = np.std(val_scores, axis=-1)
plt.semilogx(param_range, train_scores_mean, label='Training score', color='r')
plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2, color='r')
plt.semilogx(param_range, val_scores_mean, label='Val score', color='g')
plt.fill_between(param_range, val_scores_mean - val_scores_std, val_scores_mean + val_scores_std, alpha=0.2, color='g')
plt.legend(loc='best'); plt.grid()
plt.title('Validation Curve with SVR')
plt.xlabel(param_name); plt.ylabel('Accuracy')
plt.ylim(0.0, 1.1)
plt.show()
opt_idx = np.argmin(val_scores_mean)
opt_param, opt_score = param_range[opt_idx], val_scores_mean[opt_idx]
print("Optimal param:", opt_param)
print("Optimal score:", opt_score)
return opt_param, opt_score
param_range = np.logspace(-2, 0, num=100)
opt_param, opt_score = plot_validation_curve(rbf_svr, 'svm__gamma', param_range)
3. California Housing Dataset Example
0. Import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warn = lambda *args, **kargs: None
warnings.warn = warn
1. Load dataset
from sklearn.datasets import fetch_california_housing
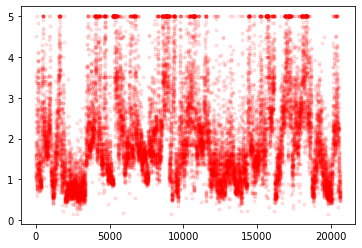
housing = fetch_california_housing()
plt.plot(housing.target, 'r.', alpha=0.1); plt.show()
** 1) Split dataset
from sklearn.model_selection import train_test_split
X, y = housing['data'], housing['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=5640)
_, X_train_5000, _, y_train_5000 = train_test_split(X_train, y_train, test_size=5000)
_, X_train_1000, _, y_train_1000 = train_test_split(X_train, y_train, test_size=1000)
print(X_train.shape, X_test.shape, X_train_5000.shape, X_train_1000.shape)
(15000, 8) (5640, 8) (5000, 8) (1000, 8)
2. Train with small data
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
poly_svr = Pipeline([
('std_scaler', StandardScaler()),
('svm', SVR(kernel='poly', degree=5, coef0=2)) # degree, coef0, C, gamma
])
rbf_svr = Pipeline([
('std_scaler', StandardScaler()),
('svm', SVR(kernel='rbf')) # C, gamma
])
from sklearn.metrics import mean_squared_error
dataset = (X_train_1000, y_train_1000)
for model, name in zip([poly_svr, rbf_svr], ['poly', 'rbf']):
X, y = dataset
%time model.fit(X, y)
y_pred = model.predict(X)
err = np.sqrt(mean_squared_error(y, y_pred))
print(f"Error of {name}: {err} \n")
CPU times: user 2.69 s, sys: 0 ns, total: 2.69 s
Wall time: 2.69 s
Error of poly: 0.4692484334754285
CPU times: user 61.8 ms, sys: 0 ns, total: 61.8 ms
Wall time: 61.6 ms
Error of rbf: 0.5855508521036734
dataset = (X_train_5000, y_train_5000)
for model, name in zip([poly_svr, rbf_svr], ['poly', 'rbf']):
X, y = dataset
%time model.fit(X, y)
y_pred = model.predict(X)
err = np.sqrt(mean_squared_error(y, y_pred))
print(f"Error of {name}: {err} \n")
CPU times: user 2min 42s, sys: 31.5 ms, total: 2min 42s
Wall time: 2min 42s
Error of poly: 0.5085922836856657
CPU times: user 1.06 s, sys: 20 ms, total: 1.08 s
Wall time: 1.08 s
Error of rbf: 0.5539729093645074
3. Hyperparameter tuning
1) C, gamma 동시에 찾기
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import reciprocal, uniform
param_dist = {'svm__gamma': reciprocal(1e-3, 1e-1), 'svm__C': uniform(1, 10)}
rnd_search = RandomizedSearchCV(rbf_svr, param_dist, cv=3, n_iter=100, scoring='neg_mean_squared_error', return_train_score=True, n_jobs=-1)
rnd_search.fit(X_train_1000, y_train_1000)
best_rnd_model = rnd_search.best_estimator_
df = pd.DataFrame(rnd_search.cv_results_)
for score in ('mean_test_score', 'mean_train_score'):
df[score] = np.sqrt(-df[score])
df[['mean_test_score', 'mean_train_score', 'param_svm__C', 'param_svm__gamma']].sort_values(by=['mean_test_score']).head()
| mean_test_score | mean_train_score | param_svm__C | param_svm__gamma | |
|---|---|---|---|---|
| 81 | 0.633934 | 0.519405 | 8.74654 | 0.0868508 |
| 15 | 0.634402 | 0.550763 | 8.13807 | 0.0628689 |
| 45 | 0.634429 | 0.560087 | 5.54477 | 0.0657398 |
| 23 | 0.634826 | 0.530044 | 5.54278 | 0.092693 |
| 54 | 0.634901 | 0.544805 | 4.77369 | 0.0850559 |
from sklearn.model_selection import GridSearchCV
param_dist = {'svm__gamma': np.logspace(-2, 0, num=20), 'svm__C': np.logspace(-1, np.log10(20), num=20)}
print("Range: C=[0.1, 20], gamma=[0.01, 1]")
grid_search = GridSearchCV(rbf_svr, param_dist, cv=3, scoring='neg_mean_squared_error', return_train_score=True, n_jobs=-1)
grid_search.fit(X_train_1000, y_train_1000)
best_grid_model = grid_search.best_estimator_
df = pd.DataFrame(grid_search.cv_results_)
for score in ('mean_test_score', 'mean_train_score'):
df[score] = np.sqrt(-df[score])
df[['mean_test_score', 'mean_train_score', 'param_svm__C', 'param_svm__gamma']].sort_values(by=['mean_test_score']).head()
Range: C=[0.1, 20], gamma=[0.01, 1]
| mean_test_score | mean_train_score | param_svm__C | param_svm__gamma | |
|---|---|---|---|---|
| 329 | 0.633774 | 0.518114 | 8.66382 | 0.0885867 |
| 290 | 0.634383 | 0.517874 | 4.96016 | 0.112884 |
| 289 | 0.634417 | 0.538857 | 4.96016 | 0.0885867 |
| 349 | 0.634426 | 0.508877 | 11.4503 | 0.0885867 |
| 288 | 0.634500 | 0.559567 | 4.96016 | 0.0695193 |
2) C, gamma 각각 찾기
from sklearn.model_selection import validation_curve
def plot_validation_curve(model, param_name, param_rage):
train_scores, val_scores = validation_curve(model, X_train_1000, y_train_1000,
param_name=param_name, param_range=param_range, cv=3, scoring='neg_mean_squared_error', n_jobs=-1)
train_scores_mean = np.mean(-train_scores, axis=-1)
train_scores_std = np.std(train_scores, axis=-1)
val_scores_mean = np.mean(-val_scores, axis=-1)
val_scores_std = np.std(val_scores, axis=-1)
plt.semilogx(param_range, train_scores_mean, label='Training score', color='r')
plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2, color='r')
plt.semilogx(param_range, val_scores_mean, label='Val score', color='g')
plt.fill_between(param_range, val_scores_mean - val_scores_std, val_scores_mean + val_scores_std, alpha=0.2, color='g')
plt.legend(loc='best'); plt.grid()
plt.title('Validation Curve with SVR')
plt.xlabel(param_name); plt.ylabel('Accuracy')
plt.ylim(0.0, 1.1)
plt.show()
opt_idx = np.argmin(val_scores_mean)
opt_param, opt_score = param_range[opt_idx], val_scores_mean[opt_idx]
print("Optimal param:", opt_param)
print("Optimal score:", opt_score)
return opt_param, opt_score
param_range = np.logspace(-5, -1, num=100)
opt_param, opt_score = plot_validation_curve(rbf_svr, 'svm__gamma', param_range)
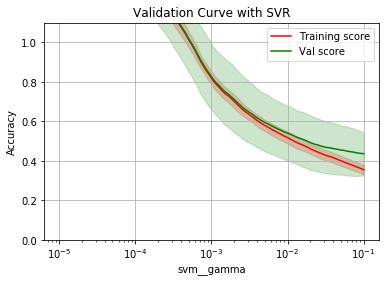
Optimal param: 0.1
Optimal score: 0.43650768517511124
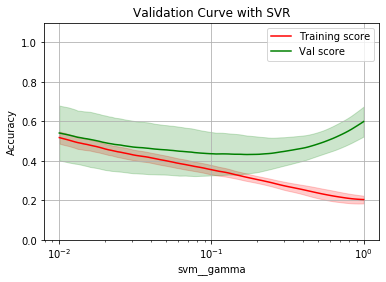
param_range = np.logspace(-2, 0, num=100)
opt_param, opt_score = plot_validation_curve(rbf_svr, 'svm__gamma', param_range)
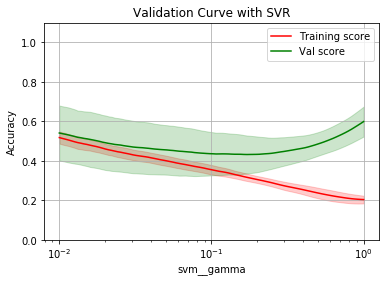
Optimal param: 0.17073526474706913
Optimal score: 0.4324826287038535
from sklearn.base import clone
fined_rbf_svr = clone(rbf_svr).set_params(svm__gamma=opt_param)
param_range = np.logspace(-1, np.log10(60), num=100)
opt_param, opt_score = plot_validation_curve(rbf_svr, 'svm__C', param_range)
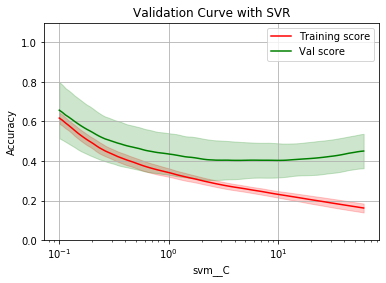
Optimal param: 9.826786098841604
Optimal score: 0.4032222972428697
fined_rbf_svr = clone(fined_rbf_svr).set_params(svm__C=opt_param)
X, y = (X_train_1000, y_train_1000)
for model, name in zip([best_rnd_model, fined_rbf_svr], ['best rnd model', 'fined model']):
model.fit(X, y)
y_pred = model.predict(X)
err = np.sqrt(mean_squared_error(y, y_pred))
print(f"{name}:", err)
best rnd model: 0.537314162153041
fined model: 0.47465599605274217
best_model = fined_rbf_svr
4. Final score
%time best_model.fit(X_train, y_train)
y_train_pred = best_model.predict(X_train)
y_test_pred = best_model.predict(X_test)
err_train = np.sqrt(mean_squared_error(y_train, y_train_pred))
err_test = np.sqrt(mean_squared_error(y_test, y_test_pred))
print("\nTrain err:", err_train)
print("Test err:", err_test)
CPU times: user 16.8 s, sys: 39.9 ms, total: 16.8 s
Wall time: 16.9 s
Train err: 0.5326520782490112
Test err: 0.5503960446545103