Remarks
이 글은 CS231n 강의를 기반으로 작성되었습니다.
1. Preprocess data
- Zero-center: 각 feature의 평균이 0가 되지 않으면 gradient의 부호가 자유롭게 정해지지 않기 때문에 zigzag path로 학습되어 비효율적이다.
- Normalization: 모든 feature들이 동일한 범위 안에 있도록 하여 모두 동등하게 분포하지 않으면 마찬가지로 zigzag path로 학습되어 비효율적이다.
2. Choose the architecture
3. Double check that the loss is reasonable
- Regularization을 사용하지 않고, loss가 생각대로 나오는지 확인한다.
그리고 regularization을 사용하여 loss가 증가하는지 체크한다.(sanity check)
4. Train
1) Simply train without regularization
- 아주 적은 개수의 데이터에 대하여 regularization을 사용하지 않고 학습시킨다.
- 데이터의 개수가 적기 때문에 overfitting 되기 쉬워 training loss가 좋은 결과를 보여줄 것이다.
2) Fully train with regularization
- Sanity check가 완료되었으면 전체 학습 데이터를 사용하여 적당한 learning rate를 탐색한다.
Hyperparameter optimization
- Coarse search(넓은 범위에 대해 조금씩 학습시켜 대략적인 범위를 찾는다)
- Finer search(선택한 범위에서 학습시간을 늘려 가장 적절한 값을 선택한다)
- Random search(선호) vs Grid search
- $\textit{param_scale} = \Vert W \Vert^2$
$\textit{update_scale} = \Vert -\eta \cdot \nabla_WL \Vert^2$
$\frac{\textit{update_scale}}{\textit{param_scale}} \approx 0.001$ 이 되도록 $\eta$를 선택하는 것이 바람직하다.
5. Monitoring and visualize the loss curve
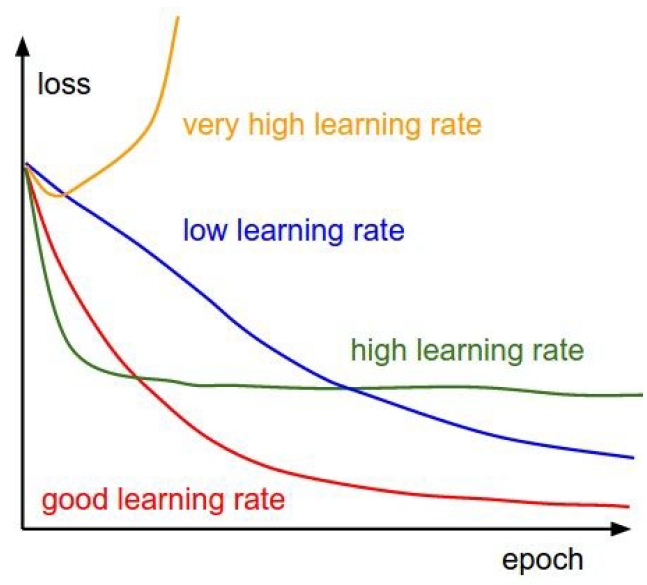
- 가장 학습이 잘 된 때는 overfitting 되기 직전이다.
PREVIOUSEtc