학습에 도움되는 여러가지 도구들을 Callback 이라는 형태로 사용할 수 있다.
Import packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import tensorflow as tf
from tensorflow import keras
1. Load dataset
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full)
2. Preprocessing
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
3. Modeling
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow_addons.metrics import RSquare
model = Sequential([
Dense(30, input_shape=X_train[0].shape, kernel_initializer='he_normal', activation='relu'),
Dense(30, kernel_initializer='he_normal', activation='relu'),
Dense(1)
])
model.compile(loss='mse', optimizer='sgd', metrics=[RSquare(y_shape=(1,))])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 30) 270
_________________________________________________________________
dense_1 (Dense) (None, 30) 930
_________________________________________________________________
dense_2 (Dense) (None, 1) 31
=================================================================
Total params: 1,231
Trainable params: 1,231
Non-trainable params: 0
_________________________________________________________________
4. Training
4.1 Prepare Callbacks
import os
os.makedirs('ckpt', exist_ok=True)
os.makedirs('result', exist_ok=True)
os.makedirs('tensorboard', exist_ok=True)
from tensorflow.keras.callbacks import Callback
class LossPlot(Callback):
def __init__(self, dir_path, figsize=(15, 8)):
self.dir_path = dir_path
self.figsize = figsize
mkdir(self.dir_path)
self.metrics = pd.DataFrame()
self.best_epoch = -1
def on_epoch_end(self, epoch, logs={}):
self.metrics = self.metrics.append(logs, ignore_index=True)
self.best_epoch = np.argmin(self.metrics['val_loss'])
self._save_fig(epoch)
def _save_fig(self, epoch):
fig, ax = plt.subplots(figsize=self.figsize)
for col in self.metrics:
self.metrics[col].plot(linestyle='-' if 'loss' in col else '--', color='r' if col.startswith('val') else 'b', ax=ax)
ax.axvline(self.best_epoch, color='k', ls=':', lw=3)
ax.set_xlabel('epoch'); ax.set_ylabel('metric')
ax.set_yscale('log')
ax.legend(loc='upper right')
fig.tight_layout()
fig.savefig(join(self.dir_path, 'metrics.png'))
plt.close(fig)
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, CSVLogger, ReduceLROnPlateau, TensorBoard
callbacks = [
ModelCheckpoint('ckpt/[{epoch:03d} epoch] val_loss: {val_loss:.4f}.h5', save_best_only=True),
EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True),
CSVLogger('result/logs.csv'),
ReduceLROnPlateau(monitor='val_loss', factor=0.9, patience=5, verbose=1),
TensorBoard('tensorboard', write_graph=True, write_images=True),
LossPlot('result')
]
4.2 Training
history = model.fit(X_train, y_train, epochs=100, validation_data=(X_valid, y_valid), callbacks=callbacks, use_multiprocessing=True)
Epoch 1/100
1/363 [..............................] - ETA: 3:11 - loss: 14.5933 - r_square: -7.8717WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0015s vs `on_train_batch_end` time: 0.0047s). Check your callbacks.
363/363 [==============================] - 1s 2ms/step - loss: 1.0000 - r_square: 0.2456 - val_loss: 0.5235 - val_r_square: 0.6158
Epoch 2/100
363/363 [==============================] - 1s 2ms/step - loss: 1.8754 - r_square: -0.4148 - val_loss: 0.5246 - val_r_square: 0.6150
Epoch 3/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4900 - r_square: 0.6304 - val_loss: 0.4827 - val_r_square: 0.6458
Epoch 4/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4541 - r_square: 0.6574 - val_loss: 0.4621 - val_r_square: 0.6609
Epoch 5/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4350 - r_square: 0.6718 - val_loss: 0.4426 - val_r_square: 0.6752
Epoch 6/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4269 - r_square: 0.6780 - val_loss: 0.4535 - val_r_square: 0.6672
Epoch 7/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4133 - r_square: 0.6882 - val_loss: 0.4336 - val_r_square: 0.6818
Epoch 8/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4129 - r_square: 0.6885 - val_loss: 0.4310 - val_r_square: 0.6837
Epoch 9/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4005 - r_square: 0.6979 - val_loss: 0.4155 - val_r_square: 0.6951
Epoch 10/100
363/363 [==============================] - 1s 2ms/step - loss: 0.4270 - r_square: 0.6779 - val_loss: 0.4259 - val_r_square: 0.6874
Epoch 11/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3995 - r_square: 0.6986 - val_loss: 0.4047 - val_r_square: 0.7030
Epoch 12/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3810 - r_square: 0.7126 - val_loss: 0.4062 - val_r_square: 0.7019
Epoch 13/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3785 - r_square: 0.7145 - val_loss: 0.3947 - val_r_square: 0.7104
Epoch 14/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3708 - r_square: 0.7203 - val_loss: 0.3936 - val_r_square: 0.7112
Epoch 15/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3668 - r_square: 0.7233 - val_loss: 0.3924 - val_r_square: 0.7120
Epoch 16/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3644 - r_square: 0.7251 - val_loss: 0.3837 - val_r_square: 0.7184
Epoch 17/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3587 - r_square: 0.7294 - val_loss: 0.3829 - val_r_square: 0.7190
Epoch 18/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3556 - r_square: 0.7318 - val_loss: 0.3867 - val_r_square: 0.7163
Epoch 19/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3534 - r_square: 0.7334 - val_loss: 0.3687 - val_r_square: 0.7294
Epoch 20/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3476 - r_square: 0.7378 - val_loss: 0.3658 - val_r_square: 0.7315
Epoch 21/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3449 - r_square: 0.7398 - val_loss: 0.3701 - val_r_square: 0.7284
Epoch 22/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3431 - r_square: 0.7411 - val_loss: 0.3882 - val_r_square: 0.7151
Epoch 23/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3391 - r_square: 0.7442 - val_loss: 0.3668 - val_r_square: 0.7308
Epoch 24/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3379 - r_square: 0.7451 - val_loss: 0.3720 - val_r_square: 0.7270
Epoch 25/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3337 - r_square: 0.7483 - val_loss: 0.3542 - val_r_square: 0.7401
Epoch 26/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3328 - r_square: 0.7490 - val_loss: 0.3630 - val_r_square: 0.7336
Epoch 27/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3302 - r_square: 0.7509 - val_loss: 0.3510 - val_r_square: 0.7425
Epoch 28/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3289 - r_square: 0.7519 - val_loss: 0.3510 - val_r_square: 0.7424
Epoch 29/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3276 - r_square: 0.7528 - val_loss: 0.3640 - val_r_square: 0.7329
Epoch 30/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3243 - r_square: 0.7553 - val_loss: 0.3564 - val_r_square: 0.7384
Epoch 31/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3226 - r_square: 0.7567 - val_loss: 0.3566 - val_r_square: 0.7383
Epoch 32/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3208 - r_square: 0.7580 - val_loss: 0.3590 - val_r_square: 0.7366
Epoch 00032: ReduceLROnPlateau reducing learning rate to 0.008999999798834325.
Epoch 33/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3173 - r_square: 0.7606 - val_loss: 0.3526 - val_r_square: 0.7413
Epoch 34/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3152 - r_square: 0.7622 - val_loss: 0.3538 - val_r_square: 0.7404
Epoch 35/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3136 - r_square: 0.7635 - val_loss: 0.3512 - val_r_square: 0.7423
Epoch 36/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3121 - r_square: 0.7645 - val_loss: 0.3504 - val_r_square: 0.7429
Epoch 37/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3119 - r_square: 0.7647 - val_loss: 0.3304 - val_r_square: 0.7576
Epoch 38/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3112 - r_square: 0.7653 - val_loss: 0.3497 - val_r_square: 0.7434
Epoch 39/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3082 - r_square: 0.7675 - val_loss: 0.3335 - val_r_square: 0.7553
Epoch 40/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3096 - r_square: 0.7664 - val_loss: 0.3332 - val_r_square: 0.7555
Epoch 41/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3090 - r_square: 0.7669 - val_loss: 0.3276 - val_r_square: 0.7596
Epoch 42/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3076 - r_square: 0.7680 - val_loss: 0.3297 - val_r_square: 0.7581
Epoch 43/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3054 - r_square: 0.7696 - val_loss: 0.3339 - val_r_square: 0.7550
Epoch 44/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3055 - r_square: 0.7695 - val_loss: 0.3702 - val_r_square: 0.7283
Epoch 45/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3057 - r_square: 0.7694 - val_loss: 0.3333 - val_r_square: 0.7554
Epoch 46/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3042 - r_square: 0.7705 - val_loss: 0.3329 - val_r_square: 0.7557
Epoch 00046: ReduceLROnPlateau reducing learning rate to 0.008099999651312828.
Epoch 47/100
363/363 [==============================] - 1s 2ms/step - loss: 0.3015 - r_square: 0.7726 - val_loss: 0.3366 - val_r_square: 0.7530
Epoch 48/100
363/363 [==============================] - 1s 2ms/step - loss: 0.2990 - r_square: 0.7744 - val_loss: 0.3514 - val_r_square: 0.7421
Epoch 49/100
363/363 [==============================] - 1s 2ms/step - loss: 0.2993 - r_square: 0.7742 - val_loss: 0.3492 - val_r_square: 0.7438
Epoch 50/100
363/363 [==============================] - 1s 2ms/step - loss: 0.2995 - r_square: 0.7741 - val_loss: 0.3326 - val_r_square: 0.7559
Epoch 51/100
363/363 [==============================] - 1s 2ms/step - loss: 0.2986 - r_square: 0.7748 - val_loss: 0.3434 - val_r_square: 0.7480
Epoch 00051: ReduceLROnPlateau reducing learning rate to 0.007289999350905419.
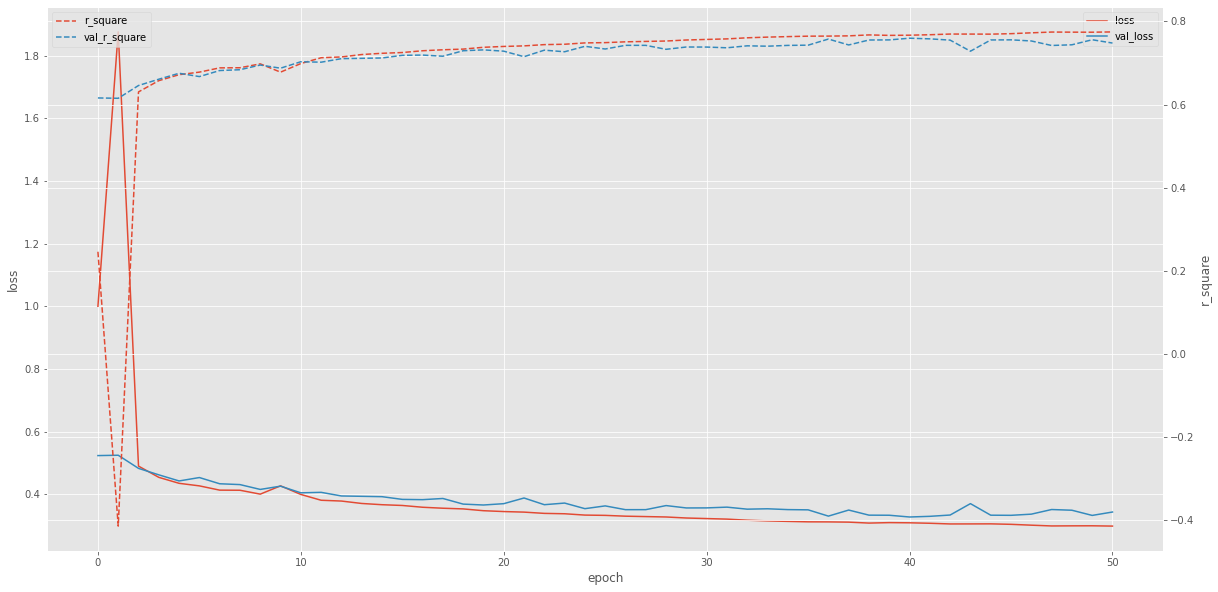
fig, ax = plt.subplots(figsize=(20, 10))
ax_twin = ax.twinx()
pd.DataFrame(history.history, columns=['loss', 'val_loss']).plot(xlabel='epoch', ylabel='loss', ax=ax)
pd.DataFrame(history.history, columns=['r_square', 'val_r_square']).plot(linestyle='--', ylabel='r_square', ax=ax_twin);
5. Evaluation
model.evaluate(X_test, y_test)
162/162 [==============================] - 0s 1ms/step - loss: 0.3388 - r_square: 0.7435
[0.3387697637081146, 0.7434945702552795]
X_new = X_test[:3]
y_pred = model.predict(X_new); y_pred
array([[3.197331 ],
[2.6825705],
[1.7492278]], dtype=float32)
PREVIOUSEtc