Remarks
이 글은 인하대학교 최동완 교수님의 빅데이터컴퓨팅 수업을 정리한 자료입니다.
1. Course Overview
1) True course name
Algorithms and Data Structures to deal with Big Data
2) What about?
How to process and analyze Big Data in an algorithmic perspective
3) Not about
ML, how to use Big Data platforms
4) About
CS theory course (data structures, algorithms, discrete math, probability)
5) Major topics
- What is Big Data?
- Fundumental problems in Big data
- Intro to Randomized Algorithms(Quick sort, Min-cut algorithm)
- Membership problem(Bloom filter)
- Stream data processing(Frequency estimation, counting problem)
- Similarity search(Locality-sensitive hashing for high-dimensional data)
- Parallel data processing platforms(Map Reduce, Spark in the theoretical point of view)
2. What is Big Data?
Big Data Broad general term for data sets so large and complex that traditional data processing and storage techniques(traditional RDBMs, deterinistic algo., main memory algo., algorithms running on a single machine) are inadequate Big Data(scalability) $\approx$ Data Science(statistical aspects, accuracy) $\supset$ Maching Learning
1) How Statisticians See Data Science
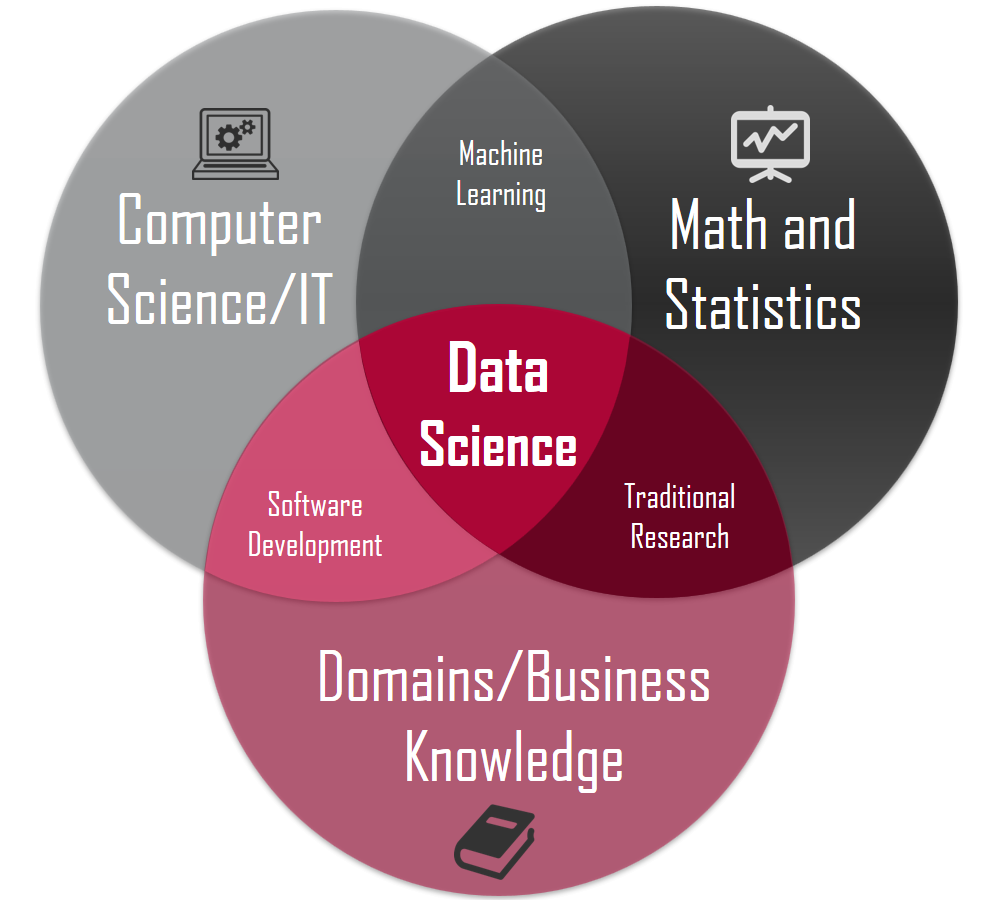 1
In fact, many data scientists are in Software Development
1
In fact, many data scientists are in Software Development
2) How Computer Scientists See Data Science
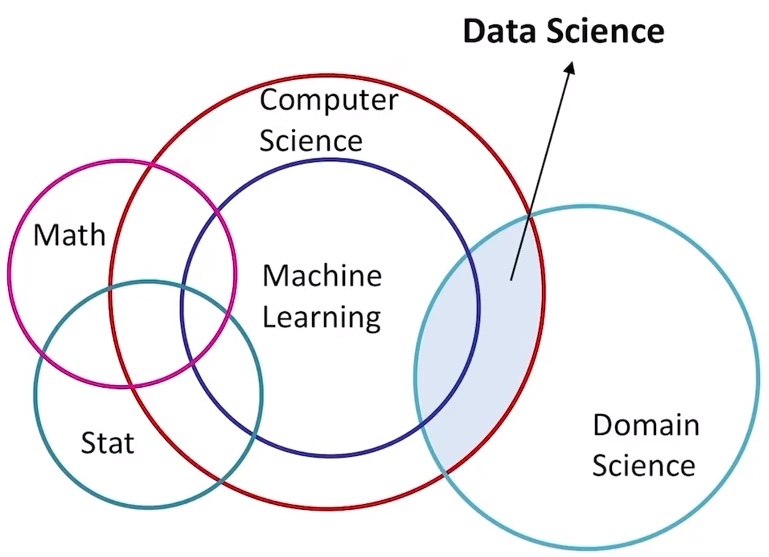 2
Math and Statistics don’t deliver data science directly, only do it though the algo.(e.g. ML algo.)
2
Math and Statistics don’t deliver data science directly, only do it though the algo.(e.g. ML algo.)
3) The words keep changing (re-branding)
Data Mining(2000) → Big Data(2010) → Data Science(2017)
4) V’s of Big Data
-
Volume (scale of data) By 2025, the global data will grow to 175ZB(175 * 10$^9$TB) 300 hours of video to YouTube per minute
-
Velocity (fast generated, streaming data) Modern cars have at least 100 sensors that monitor items
- Variety (high-dimensional, unstructured)
Most of data is not stored at Database
- 400 million tweets per day
- 4 billion hours of video per day
- 420 million wearable health monitors
- 30 billion Facebook contents shared per month
- Veracity (high uncertainty) Poor data quality costs the US economy around 3.1 trillion USD per year (fake news, social media data)
3. What to do with Big Data?
1) Knowledge Extraction from Data
Data → Information → Knowledge
- 3 steps are needed for Big Data(Data Science)
- Stored (Data Engineering)
- Managed (Data Engineering)
- Analyzed (Data Mining, Data Engineering, Data Scientist, Data Analyst)
$\Rightarrow$ Big Data: Data Enginnering and Data Mining technologies particularly for Very Large Data
2) Problems
- Heterogenous data(unstructured, and various format) by multiple sources
- Deterministic algo. → Randomized algo.(Focus!)
- Main-memory algo. → External-memory algo. (I/O number matters)
- Storage systems(DBs) → Big data processing platforms(Hadoop, Spark)
3) Data Scientist / Data Engineering
- Data Scientist: All + Math!
- Data Engineering: All + System, coding!
-
https://towardsdatascience.com/introduction-to-statistics-e9d72d818745 ↩
-
It is said to be Jeffrey’s point of view. (https://en.wikipedia.org/wiki/Jeffrey_Ullman) ↩