import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
Parameters
RANDOM_STATE = 42
LABELED_RATIO = 0.05 # 5%
N_CLUSTERS = 50 # labeling이 충분히 가능하다면, cluster의 개수를 크게 잡는 것이 좋다
1. Load data
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
np.random.seed(RANDOM_STATE)
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=RANDOM_STATE)
X_train_org, X_test_org = X_train.copy(), X_test.copy()
X_train.shape, y_train.shape, X_test.shape, y_test.shape
((1347, 64), (1347,), (450, 64), (450,))
2. Label propagation
2.1 Select representative image
from sklearn.cluster import KMeans
kmeans = KMeans(opt_n_clusters, random_state=RANDOM_STATE)
X_train_affinity = kmeans.fit_transform(X_train)
idxs_representative = np.argmin(X_train_affinity, axis=0) # closest sample to the centroid
X_train_representative = X_train[idxs_representative]
2.2 Manual labeling (expert)
X_train_org_representative = X_train_org[idxs_representative]
fig, axes = plt.subplots(1, opt_n_clusters, figsize=(15, 1))
for idx_ax, ax in enumerate(axes.flat):
if idx_ax < len(X_train_org_representative):
ax.imshow(X_train_org_representative[idx_ax].reshape(8, 8), 'binary')
ax.axis('off')
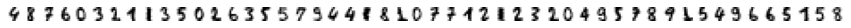
y_train_representative = np.array([4, 8, 7, 6, 0, 3, 2, 1, 1, 3, 5, 0, 2, 6, 3, 5, 5, 7, 9, 4, 4, 1, 8, 1, 0, 7, 7, 1, 2, 1, 2, 3, 2, 0, 4, 9, 5, 7, 8, 9, 1, 5, 4, 9, 6, 6, 5, 1, 5, 8])
2.3 Label propagation
2.3.1 Propagation for all data
y_train_propagated_all = np.empty(len(y_train))
for idx_cluster in range(opt_n_clusters):
y_train_propagated_all[kmeans.labels_ == idx_cluster] = y_train_representative[idx_cluster]
2.3.2 Propagation for reliable data
def get_propagated_reliable(reliable_ratio):
idxs_clusters = []
for idx_cluster in range(opt_n_clusters):
idxs = np.argsort(X_train_affinity[kmeans.labels_ == idx_cluster, idx_cluster])
idxs = idxs[:np.ceil(reliable_ratio*len(idxs)).astype(int)]
idxs_clusters.append(idxs)
return np.concatenate([X_train[kmeans.labels_ == idx_cluster][idxs] for idx_cluster, idxs in enumerate(idxs_clusters)]), \
np.concatenate([np.repeat(y_train_representative[idx_cluster], len(idxs)) for idx_cluster, idxs in enumerate(idxs_clusters)])
3. Evaluation
idxs_labeled = np.random.choice(len(X_train), int(LABELED_RATIO*len(X_train)))
X_train_random, y_train_random = X_train[idxs_labeled], y_train[idxs_labeled]
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, f1_score
model = SVC(random_state=RANDOM_STATE)
result = pd.DataFrame(columns=['train_accuracy', 'train_f1_score', 'test_accuracy', 'test_f1_score'])
for exp_name, X, y in zip(
['Full (100%)', f'Random ({100*LABELED_RATIO}%)', f'Representative ({100*LABELED_RATIO}%)', f'Propagated (20%)', f'Propagated (40%)', f'Propagated (60%)', f'Propagated (80%)', f'Propagated (100%)'],
[X_train, X_train_random, X_train_representative, get_propagated_reliable(0.2)[0], get_propagated_reliable(0.4)[0], get_propagated_reliable(0.6)[0], get_propagated_reliable(0.8)[0], get_propagated_reliable(1)[0]],
[y_train, y_train_random, y_train_representative, get_propagated_reliable(0.2)[1], get_propagated_reliable(0.4)[1], get_propagated_reliable(0.6)[1], get_propagated_reliable(0.8)[1], get_propagated_reliable(1)[1]]
):
model.fit(X, y)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
result.loc[exp_name] = [accuracy_score(y_train, y_train_pred), f1_score(y_train, y_train_pred, average='macro'), accuracy_score(y_test, y_test_pred), f1_score(y_test, y_test_pred, average='macro')]
result.index.name = model.__class__.__name__
result
| train_accuracy | train_f1_score | test_accuracy | test_f1_score | |
|---|---|---|---|---|
| SVC | ||||
| Full (100%) | 0.998515 | 0.998524 | 0.991111 | 0.991071 |
| Random (5.0%) | 0.732739 | 0.716331 | 0.722222 | 0.698227 |
| Representative (5.0%) | 0.859688 | 0.854053 | 0.848889 | 0.835384 |
| Propagated (20%) | 0.947290 | 0.947040 | 0.940000 | 0.939079 |
| Propagated (40%) | 0.960653 | 0.960496 | 0.955556 | 0.954870 |
| Propagated (60%) | 0.962880 | 0.962813 | 0.957778 | 0.957274 |
| Propagated (80%) | 0.959911 | 0.959987 | 0.960000 | 0.959517 |
| Propagated (100%) | 0.956941 | 0.956851 | 0.953333 | 0.952689 |
PREVIOUSEtc