Import packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import tensorflow as tf
from tensorflow import keras
1. Load dataset
from keras.datasets import fashion_mnist
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
class_names = np.array(['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'])
n_classes = len(class_names)
enc = OneHotEncoder(sparse=False)
y_train_full = enc.fit_transform(y_train_full[:, None])
y_test = enc.transform(y_test[:, None])
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full)
X_train.shape, y_train.shape, X_valid.shape, y_valid.shape, X_test.shape, y_test.shape
((45000, 28, 28),
(45000, 10),
(15000, 28, 28),
(15000, 10),
(10000, 28, 28),
(10000, 10))
2. Preprocessing
X_train, X_valid, X_test = X_train/255, X_valid/255, X_test/255
3. Modeling
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow_addons.metrics import F1Score
from tensorflow.keras.metrics import AUC
model = Sequential([
Flatten(input_shape=X_train[0].shape),
Dense(300, activation='relu'),
Dense(100, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy', F1Score(num_classes=n_classes), AUC()])
model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_6 (Flatten) (None, 784) 0
_________________________________________________________________
dense_18 (Dense) (None, 300) 235500
_________________________________________________________________
dense_19 (Dense) (None, 100) 30100
_________________________________________________________________
dense_20 (Dense) (None, 10) 1010
=================================================================
Total params: 266,610
Trainable params: 266,610
Non-trainable params: 0
_________________________________________________________________
4. Training
history = model.fit(X_train, y_train, epochs=5, validation_data=(X_valid, y_valid))
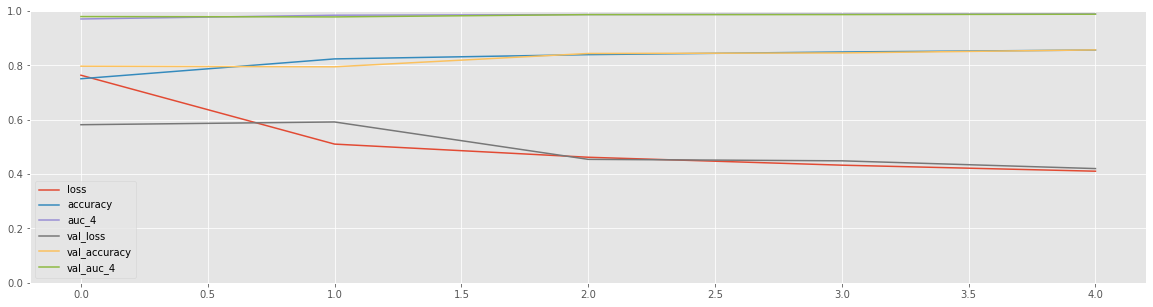
pd.DataFrame(history.history).plot(figsize=(20, 5), xlabel='epoch', ylabel='score', ylim=[0, 1], grid=True);
Epoch 1/5
1407/1407 [==============================] - 9s 6ms/step - loss: 0.7637 - accuracy: 0.7508 - f1_score: 0.7452 - auc_4: 0.9706 - val_loss: 0.5816 - val_accuracy: 0.7969 - val_f1_score: 0.7831 - val_auc_4: 0.9795
Epoch 2/5
1407/1407 [==============================] - 8s 6ms/step - loss: 0.5103 - accuracy: 0.8238 - f1_score: 0.8225 - auc_4: 0.9845 - val_loss: 0.5917 - val_accuracy: 0.7947 - val_f1_score: 0.7769 - val_auc_4: 0.9783
Epoch 3/5
1407/1407 [==============================] - 8s 6ms/step - loss: 0.4619 - accuracy: 0.8394 - f1_score: 0.8386 - auc_4: 0.9869 - val_loss: 0.4542 - val_accuracy: 0.8437 - val_f1_score: 0.8423 - val_auc_4: 0.9867
Epoch 4/5
1407/1407 [==============================] - 8s 6ms/step - loss: 0.4328 - accuracy: 0.8492 - f1_score: 0.8485 - auc_4: 0.9883 - val_loss: 0.4488 - val_accuracy: 0.8457 - val_f1_score: 0.8427 - val_auc_4: 0.9868
Epoch 5/5
1407/1407 [==============================] - 8s 6ms/step - loss: 0.4106 - accuracy: 0.8563 - f1_score: 0.8557 - auc_4: 0.9892 - val_loss: 0.4202 - val_accuracy: 0.8569 - val_f1_score: 0.8531 - val_auc_4: 0.9882
5. Evaluation
model.evaluate(X_test, y_test)
313/313 [==============================] - 1s 4ms/step - loss: 0.4436 - accuracy: 0.8466 - f1_score: 0.8426 - auc_4: 0.9871
[0.4435865581035614,
0.8465999960899353,
array([0.8121442 , 0.9651691 , 0.7502517 , 0.84112155, 0.74411464,
0.9405242 , 0.5812065 , 0.9193154 , 0.93034357, 0.94147325],
dtype=float32),
0.9870746731758118]
X_new = X_test[:3]
y_proba = model.predict(X_new); y_proba.round(2)
array([[0. , 0. , 0. , 0. , 0. , 0.16, 0. , 0.14, 0. , 0.69],
[0. , 0. , 0.98, 0. , 0. , 0. , 0.02, 0. , 0. , 0. ],
[0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ]],
dtype=float32)
y_pred = model.predict(X_new).argmax(axis=-1)
class_names[y_pred]
array(['Ankle boot', 'Pullover', 'Trouser'], dtype='<U11')
PREVIOUSEtc