Remarks
본 글은 SQL Server(T-SQL)을 기준으로 작성되었습니다.
명령어(예약어)는 CAPITAL LETTER, table 이름과 같은 고유명사는 <small letter>로 표현
USE: Database 선택
USE <database>
Database 이름, column명 등에서 대소문자는 구분하지 않는다.
tempdb: 임시 DB로 사용가능
USE tempdb
SQL Server 서비스가 재가동되면 tempdb내부의 내용은 모두 삭제됨
SELECT: Table 내에서 원하는 정보를 추출
[WITH <expression>]
SELECT <columns> [INTO <new_table>]
[FROM <table>] [WHERE <condition>]
[GROUP BY <expression>]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC]]
순서가 중요!
SELECT - FROM - WHERE - GROUP BY - HAVING - ORDER BY
- Full name of table
instance.database.schema.tableinstance이름 생략 가능USE로database이름 생략 가능schema생략 시,dboschema로 인식
SELECT * FROM <instance>.<database>.<schema>.<table>
USE database
SELECT * FROM <table> -- database.dbo.table
- Alias of column
SELECT <column> AS <alias> FROM <table>
SELECT userID AS [사용자] FROM <table> -- [alias] 사용 가능
SELECT <column> <alias> FROM <table>
SELECT [<column>]=<alias> FROM <table>
- WHERE
<cond1> AND|OR <cond2> -- multiple conditions
<col> BETWEEN <v1> AND <v2> -- <col> >= <v1> AND <col> <= <v2> 와 동일
<col> IN (<v1>, <v2>) -- <col> = <v1> OR <col> = <v2> 와 동일
<col> RLIKE '<v1>|<v2>'
<col> LIKE '김%' -- '김'으로 시작하는 문자열을 filtering
<col> RLIKE '^김'
<col> LIKE '_종신' -- `종신`으로 끝나는 3글자 문자열을 filtering
<col> RLIKE '종신$'
※ Wildcard 사용 시, index 사용 X
SELECT * FROM <table> WHERE <col> > ALL(select <col> FROM <table> WHERE <cond>) -- Subquery
SELECT * FROM <table> WHERE <col> > ANY(select <col> FROM <table> WHERE <cond>) -- Subquery
- ORDER BY
SELECT <col> FROM <table> ORDER BY <col1>, <col2> DESC -- default: ASC
- TOP: 상위 row만 선택
- MySQL에서는
limit사용SELECT TOP(10) <col> FROM <table> ORDER BY <col> -- 상위 10개 row만 선택 SELECT TOP(0.1) PERCENT <col> FROM <table> ORDER BY <col> -- 상위 0.1% row만 선택 SELECT TOP(0.1) PERCENT WITH TIES <col> FROM <table> ORDER BY <col> -- 중복값 모두 선택
- MySQL에서는
- DISTINCT: 유일한 값 선택
SELECT DISTINCT <col> FROM <table>
- COUNT: Row 개수를 반환
SELECT COUNT(*)/100 FROM <table> -- 전체 row 개수의 1%
- TABLESAMPLE: Sampling
SELECT * FROM <table> TABLESAMPLE(5 PERCENT) -- 약 5% row sampling
- OFFSET, FETCH NEXT: 상위 row를 제외하고 선택
SELECT * FROM <table> ORDER BY <col> OFFSET 4 ROWS -- 상위 4개 row 제외 [4:]
SELECT * FROM <table> ORDER BY <col> OFFSET 4 ROWS FETCH NEXT 3 ROWS ONLY -- 상위 4개 row 제외하고 3개 row 선택 [4:7]
- SELECT INTO: 결과로 table 생성
SELECT <col> INTO <table2> FROM <table1> -- PK, FK는 복사되지 않음
- GROUP BY, HAVING
SELECT <col1>, SUM(<col2>) FROM <table> GROUP BY <col1>
SELECT <col1>, SUM(<col2>*<col3>) FROM <table> GROUP BY <col1>
※ AVG(), MIN(), MAX(), COUNT(), COUNT_BIG(), STDEV(), VAR() 등의 집계함수 사용 가능
SELECT AVG(<col>*1.0) FROM <table> -- <col>의 dtype이 INT인 경우 float값(1.0)을 곱해 FLOAT로 CASTING
SELECT AVG(CAST(<col> AS DECIMAL(10,6))) FROM <table> -- 10자리, 소수점 6자리 10진수로 변환
SELECT <col1>, SUM(<col2>*<col3>) FROM <table>
GROUP BY <col1>
HAVING SUM(<col2>*<col3> > 1000) -- 집계함수에 관한 조건은 HAVING
- ROLLUP, GROUPING_ID, CUBE
소합계, 총합계를 계산ex) SELECT num, groupName, SUM(price*amount) FROM <table> GROUP BY ROLLUP (groupName, num) -- groupName, num에 대한 소합계와 총합계를 계산 SELECT num, groupName, SUM(price*amount) FROM <table> GROUP BY ROLLUP (groupName) -- groupName에 대한 총합계를 계산 SELECT num, groupName, SUM(price*amount), GROUPING_ID(groupName) AS [추가행 여부] FROM <table> GROUP BY ROLLUP (groupName) -- 추가행 여부 column 추가 SELECT prodName, color, SUM(amount) FROM <table> GROUP BY CUBE(color, prodName) - 모든 column에 대한 소합계, 총합계를 계산
- WITH
WITH절은 CTE(Common Table Expression)을 표현하기 위한 구문- 비재귀적(Non-Recursive) CTE
WITH <tmp_table1>(<cols>) AS ( <query> ) WITH <tmp_table2>(<cols>) AS ( <query which can reference tmp_table1> ) SELECT <cols> FROM <tmp_table1>, <tmp_table2> - IFNULL: Imputing NULL with constant
SELECT IFNULL(<col>, 'No name')
- CASE
CASE
WHEN <cond1>
THEN <value1>
WHEN <cond2>
THEN <value2>
ELSE <value_else>
END
ex)
select animal_type,
CASE
WHEN name is null
THEN 'No name'
ELSE name
END,
sex_upon_intake
from animal_ins
- JOIN
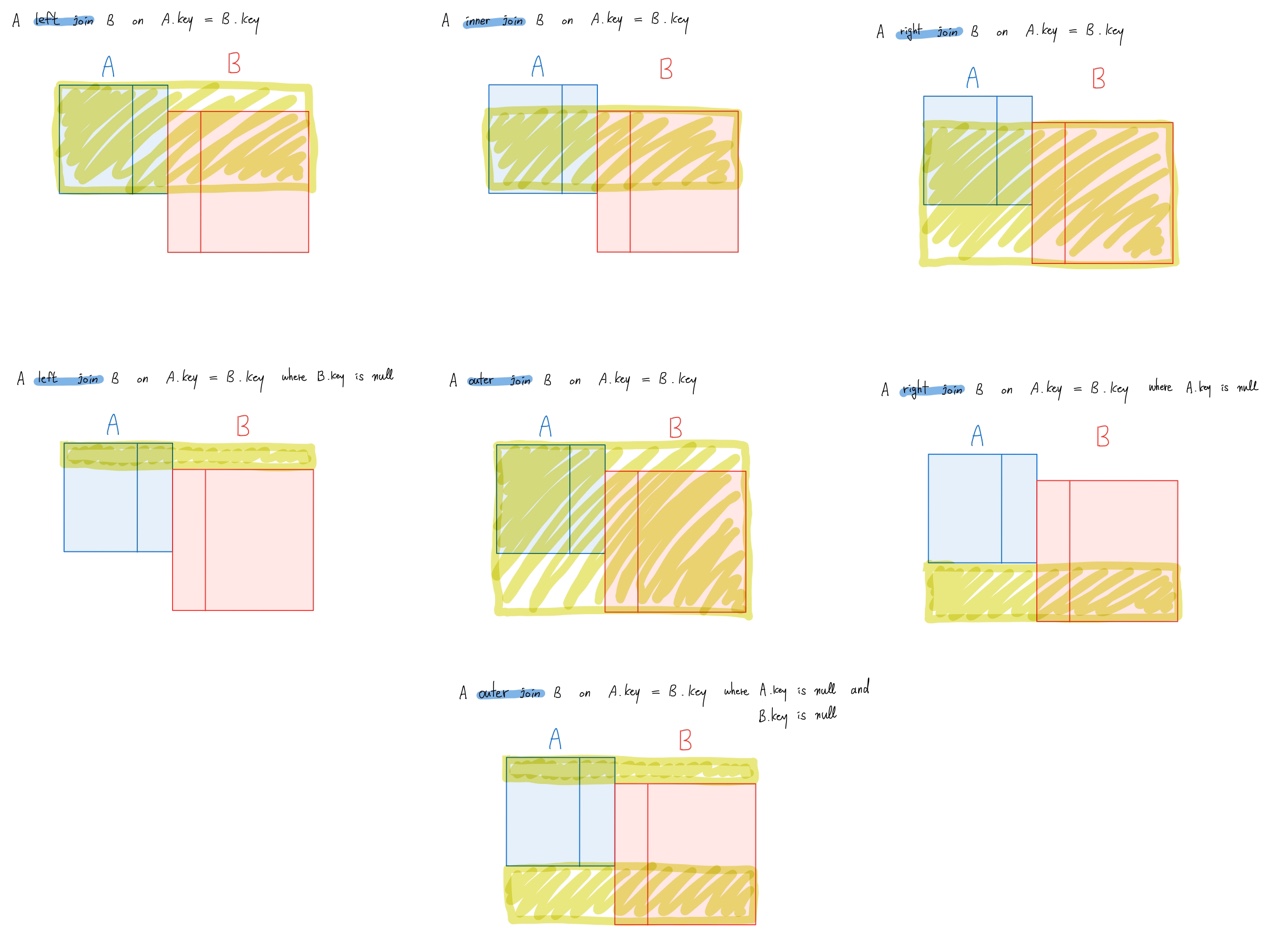
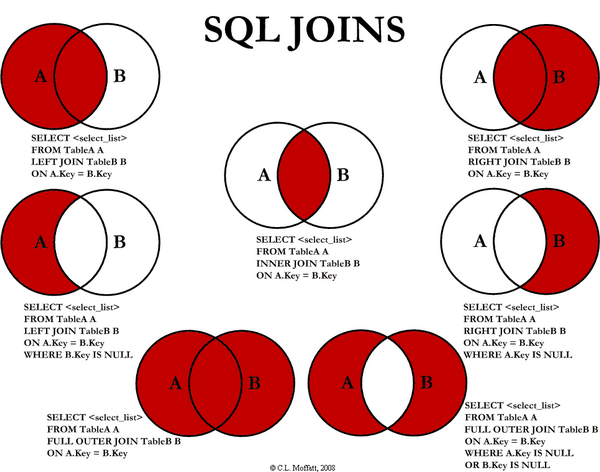
Datetime
시간을 나타내기 위해 사용하는 datatype
- 시간 추출
CONVERT()를 사용하는 것이 권장된다.- MySQL에서는 주로
DATE_FORMAT()을 사용 ``` YEAR() MONTH( ) DAY( ) HOUR( ) MINUTE( ) SECOND( )
DATE_FORMAT(
, "%Y-%m-%d %a %H:%i:%s") # 2014-05-20 Tue 11:44:00 ``` - MySQL에서는 주로
- 날짜 연산
SELECT DATEDIFF(<date1>, <date2>) # DAY diff
SELECT TIMESTAMPDIFF(HOUR, <date1>, <date2>) # SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, QUARTER, YEAR
SELECT TIMEDIFF(<date1>, <date2>) # %H:%i:%s
string->datetime
SELECT STR_TO_DATE(<str_date>, "%Y/%m/%d")
CREATE DATABASE: Database 생성
CREATE DATABASE <database>
CREATE TABLE: Table 생성
생성 예제
USE tempdb;
GO
CREATE DATABASE sqlDB;
GO
USE sqlDB;
GO
CREATE TABLE userTbl (
userID CHAR(8) NOT NULL PRIMARY KEY, -- PK
name NVARCHAR(10) NOT NULL, -- 한글 포함시, NVARCHAR
birthYear INT NOT NULL, -- 4Byte (-2,147,483,648 ~ 2,147,483,647)
addr NCHAR(2) NOT NULL DEFAULT '서울',
mobile1 CHAR(3), -- default: NULL
mobile2 CHAR(8),
height SMALLINT, -- 2Byte (-32,768 ~ 32,767)
mDate DATE
);
GO
CREATE TABLE buyTbl (
num INT IDENTITY NOT NULL PRIMARY KEY, -- IDENTITY: ID 자동 채우기
userID CHAR(8) NOT NULL FOREIGN KEY REFERENCES userTbl(userID),
prodName NCHAR(6) NOT NULL,
groupName NCHAR(4),
price INT NOT NULL,
amount SMALLINT NOT NULL
);
GO
INSERT INTO: DB에 row 추가
INSERT INTO <table> VALUES(<v1>, <v2>, ...)
INSERT INTO <table>(<col1>, <col2>, ...) VALUES(<v1>, <v2>, ...)
INSERT INTO <table>(<col1>, <col2>, ...) <query>
IDENTITYcolumn은 해당하는v가 없어야함
UPDATE: 기존의 값을 변경
UPDATE <table>
SET <col1>=<val1>, <col2>=<col1>*1.5, ...
WHERE <cond>
DELETE: Row를 제거
DELETE FROM <table>
WHERE <cond>
TRUNCATE TABLE: 전체 row 제거
TRUNCATE TABLE <table> -- 가장 빠름 (권장)
DROP TABLE <table> -- 빠름
DELETE FROM <table> -- 가장 느림
MERGE: 조건부 데이터 변경
MERGE memberTBL AS M -- 변경될 table (target)
USING changeTBL AS C -- 변경 기준 table (source)
ON M.userID = C.userID
WHEN NOT MATCHED AND changeType = '신규타입' THEN -- target table에 source table의 row가 없고, changeType='신규타입'인 경우
INSERT (userID, name, addr) VALUES(C.userID, C.name, C.addr)
WHEN MATCHED AND changeType = '주소변경' THEN -- target table에 source table의 row가 있고, changeType='주소변경'인 경우
UPDATE SET M.addr = C.addr
WHEN MATCHED AND changedType = '회원탈퇴' THEN -- target table에 source table의 row가 있고, changeType='회원탈퇴'인 경우
DELETE
CREATE VIEW: View 생성
CREATE VIEW <view>
AS
SELECT <col> FROM <table>
CREATE PROCEDURE: Procedure 생성
CREATE PROCEDURE <proc>
AS
SELECT * FROM <table1> WHERE <cond1>
SELECT * FROM <table2> WHERE <cond2>
GO
EXECUTE <proc>;
CREATE TRIGGER: Trigger 생성
SELECT * FROM memberTBL;
DELETE memberTBL where memberName = '나유타';
CREATE TABLE deletedMemberTBL
(
memberID char(8),
memberName nchar(5),
memberAddresss nchar(20),
deletedDate date
)
GO
CREATE TRIGGER trg_deleteMemberTBL
ON memberTBL
AFTER DELETE
AS
INSERT INTO deletedMemberTBL
SELECT memberID, memberName, memberAddress, GETDATE() FROM deleted;
SELECT * FROM deletedMemberTBL;
DB 정보 조회
EXECUTE sp_helpdb
USE <database>
EXECUTE sp_tables @table_type = "'TABLE'"
EXECUTE sp_columns
@table_name = <table>,
@table_owner = <schema>
BACKUP DATABASE: Database Backup
USE <database>
BACKUP DATABASE <database> TO DISK = <file_path> WITH INIT -- *.bak
PREVIOUSEtc