Notations
Association rule(연관 규칙): $X ⇒ Y$
Itemset $X, Y$ 간의 패턴
- Association rule은 직접적인 인과관계(causality)를 나타내지 않고, 상호연관성(co-occurrence)만을 알려준다.
Support(지지도)
- Support of itemset $X: P(X)$
전체 transaction 중 itemset $X$가 포함된 transaction의 비율(혹은 개수)
- Support of rule $X ⇒ Y: P(X, Y)$
전체 transaction 중 itemset $X$와 $Y$가 포함된 transaction의 비율
- Rule의 중요성에 대한 척도
Confidence(신뢰도)
Confidence of rule $X ⇒ Y: P(Y|X)$
$X$를 가진 transaction들 중 $X, Y$를 모두 가진 transaction의 비율
- Rule의 신뢰성에 대한 척도
Lift(향상도)
Lift of rule $X ⇒ Y: \frac{P(X, Y)}{P(X) P(Y)}$
Lift ↑: $X$와 $Y$가 큰 연관성을 가짐
Lift ↓: $X$와 $Y$가 작은 연관성을 가짐
- $X$와 $Y$의 독립성에 대한 척도
Frequent itemset
특정 threshold 이상의 support를 가지는 itemset
1. Association Analysis(Association Rule Mining)
Transaction에서 기준을 만족시키는 연관 규칙을 찾아내는 알고리즘
1) Algorithm
- Frequent Itemset Generation
Frequent itemset 생성 - Rule Generation
생성된 frequent itemset 중에서 높은 confidence를 가지는 rule 생성
2) Pros & Cons
- Pros
- 결과를 해석하기 쉬움
- Cons
- Item의 개수에 따라 연산량이 기하급수적으로 올라가 대용량 데이터에서 사용하기 어려움
2. Apriori Algorithm
Frequent 하지 않은 itemset의 superset 역시 frequent itemset이 아니다 라는 점을 이용하여 모든 frequent itemset을 생성하는 시간을 단축시킨 연관 분석 알고리즘
1) Algorithm
- 1개의 item을 가지는 1-itemset 생성
- 1-itemset의 support를 계산하여 frequent 1-itemset 선택
- Frequent 1-itemset에 포함된 item만으로 2개의 item을 가지는 2-itemset 생성
- 2-itemset의 support를 계산하여 frequent 2-itemset 선택
- 최대 개수의 frequent itemset이 생성될 때까지 위의 과정을 반복
2) Pros & Cons
- Pros
- 알고리즘이 간단
- 기존 association rule 알고리즘보다 빠름
3) Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
data = [['우유', '기저귀', '쥬스'],
['양상추', '기저귀', '맥주'],
['우유', '양상추', '기저귀', '맥주'],
['양상추', '맥주']]
enc = TransactionEncoder().fit(data)
df = pd.DataFrame(enc.transform(data), columns=enc.columns_)
itemsets = apriori(df, min_support=0.5, use_colnames=True)
rules = association_rules(itemsets, metric='confidence', min_threshold=0.5, support_only=False)
display(df, itemsets, rules)
기저귀 맥주 양상추 우유 쥬스
0 True False False True True
1 True True True False False
2 True True True True False
3 False True True False False
support itemsets
0 0.75 (기저귀)
1 0.75 (맥주)
2 0.75 (양상추)
3 0.50 (우유)
4 0.50 (맥주, 기저귀)
5 0.50 (기저귀, 양상추)
6 0.50 (기저귀, 우유)
7 0.75 (맥주, 양상추)
8 0.50 (맥주, 기저귀, 양상추)
antecedents consequents antecedent support consequent support support confidence lift leverage conviction
0 (맥주) (기저귀) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
1 (기저귀) (맥주) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
2 (기저귀) (양상추) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
3 (양상추) (기저귀) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
4 (기저귀) (우유) 0.75 0.50 0.50 0.67 1.33 0.12 1.50
5 (우유) (기저귀) 0.50 0.75 0.50 1.00 1.33 0.12 inf
6 (맥주) (양상추) 0.75 0.75 0.75 1.00 1.33 0.19 inf
7 (양상추) (맥주) 0.75 0.75 0.75 1.00 1.33 0.19 inf
8 (맥주, 기저귀) (양상추) 0.50 0.75 0.50 1.00 1.33 0.12 inf
9 (맥주, 양상추) (기저귀) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
10 (기저귀, 양상추) (맥주) 0.50 0.75 0.50 1.00 1.33 0.12 inf
11 (맥주) (기저귀, 양상추) 0.75 0.50 0.50 0.67 1.33 0.12 1.50
12 (기저귀) (맥주, 양상추) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
13 (양상추) (맥주, 기저귀) 0.75 0.50 0.50 0.67 1.33 0.12 1.50
3. FP-Growth
Tree 자료구조를 이용하여 frequent itemset을 생성하는 시간을 단축시킨 연관 분석 알고리즘
1) Algorithm
- 모든 item의 support를 계산
- 모든 transaction에서 frequent 하지 않은 item을 제거
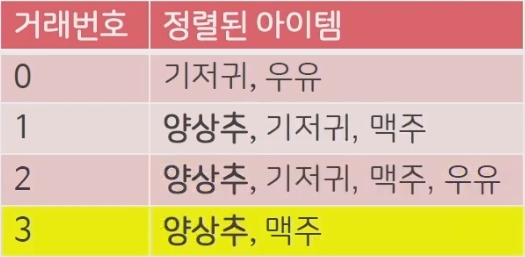
- 모든 transaction에 대하여 support를 기준으로 item을 정렬 (그림 1)
- Root node만 존재하는 tree를 생성
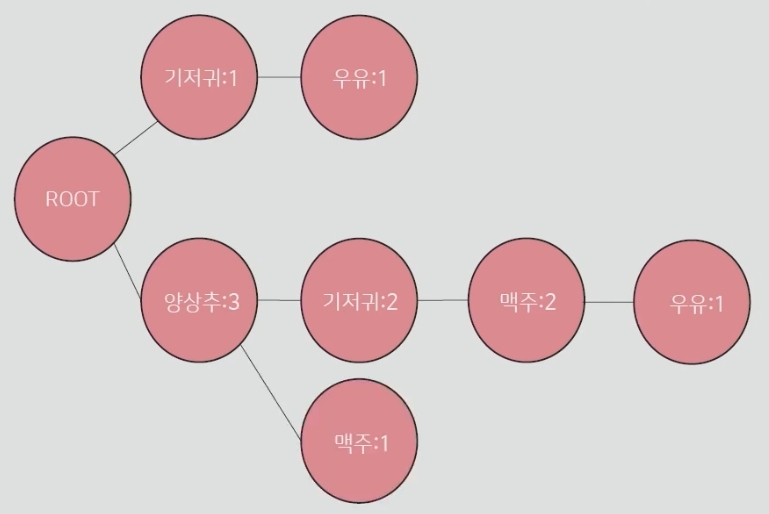
- 각각의 transaction을 root node에 일렬로 연결 (그림 2)
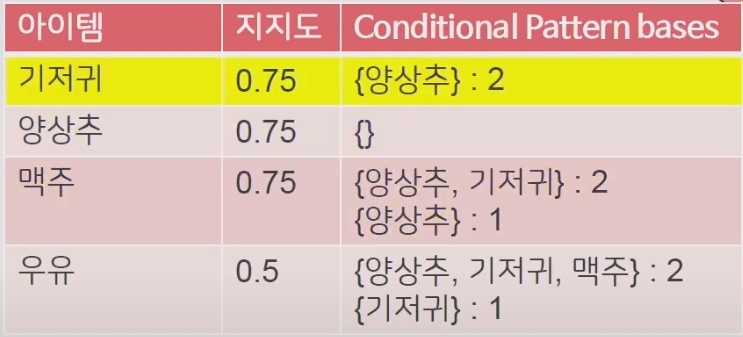
- Support가 작은 item에 해당하는 leaf node부터 root node까지 만나는 item들을 계산하여 각 item을 조건으로 하는 조건부 패턴(conditional pattern bases)을 생성 (그림 3)
- 생성된 조건부 패턴을 기반으로 패턴 생성
 |
 |
 |
|---|---|---|
| 그림 1. Support로 정렬된 transaction | 그림 2. Tree로 변환된 transaction | 그림 3. 각 item을 조건으로 하여 계산된 조건부 패턴 |
2) Pros & Cons
- Pros
- 후보 itemset들을 생성할 필요가 없고, Apriori 알고리즘보다 빠름 (2번의 탐색만 필요)
- Cons
- 메모리를 효율적으로 사용하지 못하기 때문에 대용량 데이터에 적합하지 않음
- Apriori 알고리즘에 비해 설계하기 어려움
- Support의 계산이 FP-Tree가 만들어지고 나서야 가능함
3) Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import fpgrowth
data = [['우유', '기저귀', '쥬스'],
['양상추', '기저귀', '맥주'],
['우유', '양상추', '기저귀', '맥주'],
['양상추', '맥주']]
enc = TransactionEncoder().fit(data)
df = pd.DataFrame(enc.transform(data), columns=enc.columns_)
display(df)
display(fpgrowth(df, min_support=0.5, use_colnames=True))
기저귀 맥주 양상추 우유 쥬스
0 True False False True True
1 True True True False False
2 True True True True False
3 False True True False False
support itemsets
0 0.75 (기저귀)
1 0.50 (우유)
2 0.75 (양상추)
3 0.75 (맥주)
4 0.50 (맥주, 기저귀)
5 0.50 (기저귀, 양상추)
6 0.50 (맥주, 기저귀, 양상추)
7 0.50 (기저귀, 우유)
8 0.75 (맥주, 양상추)
antecedents consequents antecedent support consequent support support confidence lift leverage conviction
0 (맥주) (기저귀) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
1 (기저귀) (맥주) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
2 (기저귀) (양상추) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
3 (양상추) (기저귀) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
4 (맥주, 기저귀) (양상추) 0.50 0.75 0.50 1.00 1.33 0.12 inf
5 (맥주, 양상추) (기저귀) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
6 (기저귀, 양상추) (맥주) 0.50 0.75 0.50 1.00 1.33 0.12 inf
7 (맥주) (기저귀, 양상추) 0.75 0.50 0.50 0.67 1.33 0.12 1.50
8 (기저귀) (맥주, 양상추) 0.75 0.75 0.50 0.67 0.89 -0.06 0.75
9 (양상추) (맥주, 기저귀) 0.75 0.50 0.50 0.67 1.33 0.12 1.50
10 (기저귀) (우유) 0.75 0.50 0.50 0.67 1.33 0.12 1.50
11 (우유) (기저귀) 0.50 0.75 0.50 1.00 1.33 0.12 inf
12 (맥주) (양상추) 0.75 0.75 0.75 1.00 1.33 0.19 inf
13 (양상추) (맥주) 0.75 0.75 0.75 1.00 1.33 0.19 inf