DocumentDB
MongoDB(3.6, 4.0, 5.0)와 호환되는 데이터베이스를 쉽게 설정, 운용 및 조정할 수 있는 빠르고 안정적인 종합 관리형 데이터베이스
Introduction
DocumentDB의 기능
- Instance-based cluster와 elastic cluster를 지원
- Elastic cluster: 초당 수백만 읽기/쓰기 및 petabytes 스토리지 워크로드를 지원 (참고)
- 이하 내용은 instance-based cluster 기준
- 스토리지 요구 사항이 증가함에 따라 자동으로 불륨 크기를 늘림 (+10GB, ~128TiB)
- 스토리지와 컴퓨팅을 분리
- Storage: 3개의 가용 영역에 걸쳐 6개의 데이터 사본을 복제
- 최대 15개의 replica instance를 생성하여 읽기 처리량을 높일 수 있음
- replica은 동일한 스토리지를 공유
- 비용이 절감
- replica 노드에서 쓰기를 수행할 필요가 없음
- 리더 엔드포인트를 제공하여 애플리케이션이 replica이 추가/제거될 때 추적할 필요 없음
- replica은 동일한 스토리지를 공유
- 각 instance의 컴퓨팅/메모리 리소스를 확장/축소 가능
- DocumentDB는 VPC에서 실행되어 격리 가능
- Cluster의 상태를 지속적으로 모니터링하며 장애 발생 시, 자동으로 재시작
- DB 프로세스와 캐시를 분리하여 재시작해도 캐시가 계속 유지
- 인스턴스 장애 시, 다른 가용 영역에 생성한 최대 15개 replica 중 하나로 자동으로 장애 조치를 수행
- replica이 프로비저닝되지 않은 경우, 자동으로 새로운 instance를 생성
- Backup 기능을 통해 cluster 복구 가능 (최근 5분까지, 최대 35일)
- 자동 백업은 S3에 저장
- 암호화(TLS) 제공
Cluster
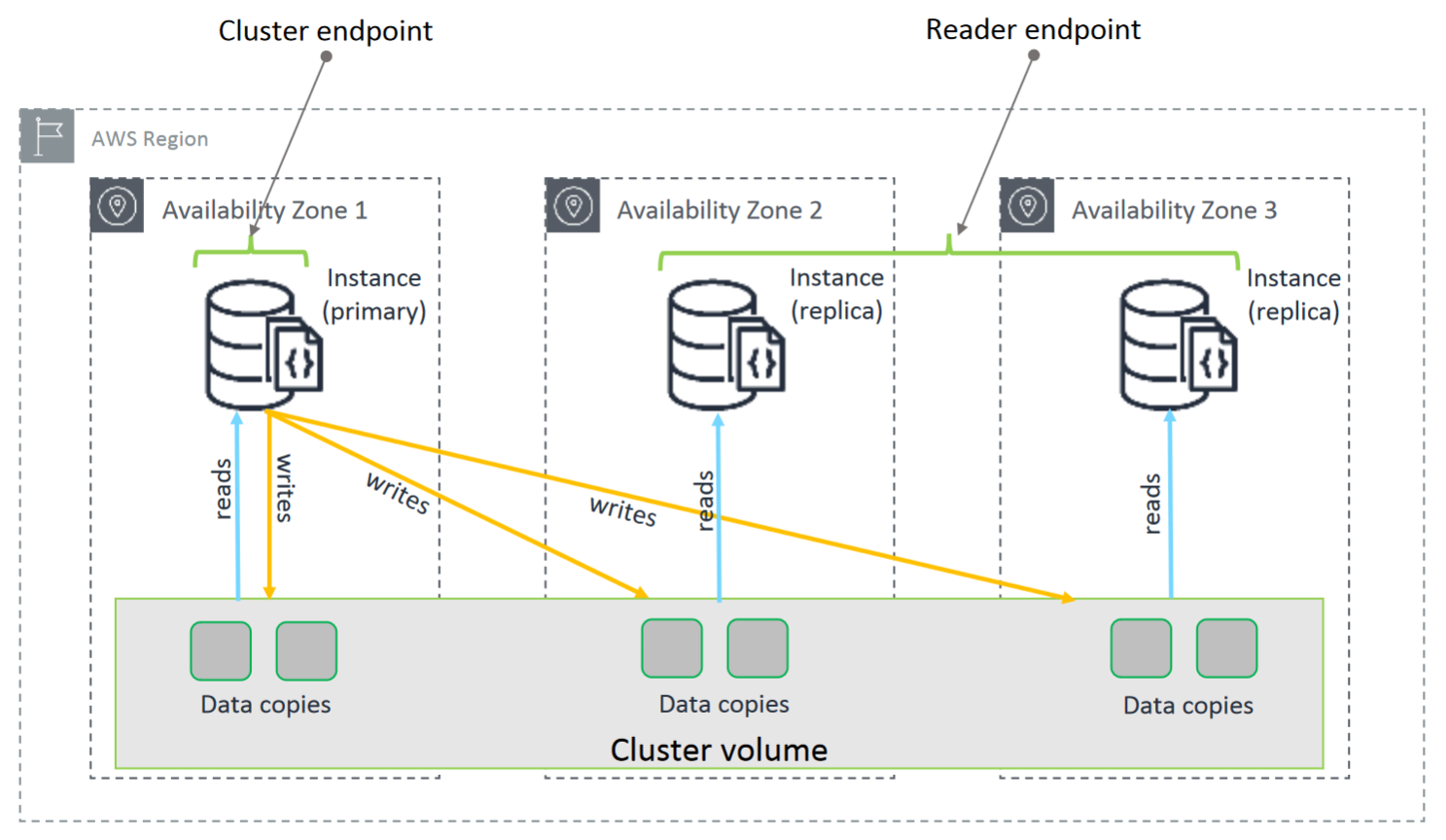
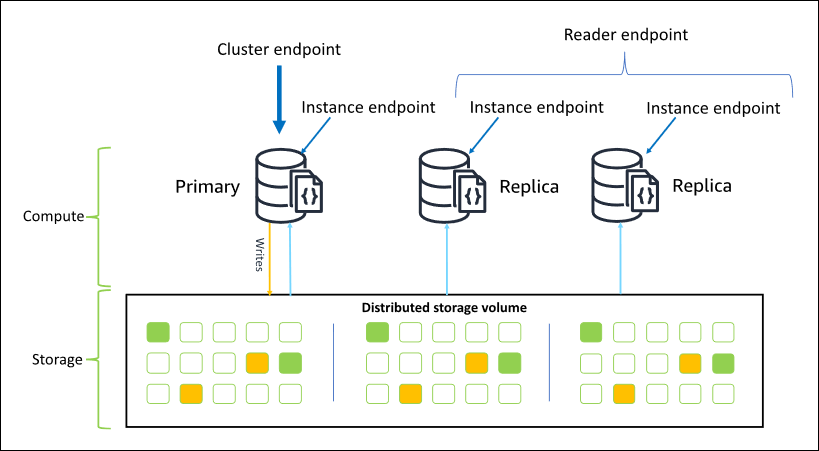
- Cluster = Instances + Cluster storage volume
- Instance는 최대 16개 가능 (원본 1개 + 복사본 15개)
- Cluster storage volume: instance의 데이터를 관리
- Cluster storage volume
Cloud native storage를 사용하여 3개의 가용 영역에 6가지 방식으로 데이터를 복제하여 저장 - Instance
Cluster storage volume에 데이터를 쓰고, 읽는 등 DB의 처리 능력을 제공 - Write: primary instance를 통해 수행
Read: 모든 instance에서 수행- Primary instance에서 승인된 write는 내구성이 강하며 롤백할 수 없음
- cluster endpoint를 통해 cluster에 접근하고, 복제 세트 모드로 cluster에 연결하는 것을 권장
- Cluster endpoint -> primary instance
- 읽기/쓰기 연결에 장애 조치 지원을 제공
- Primary instance 실패 시, 가용한 instance를 primary instance로 자동 리디렉션
- Reader endpoint -> replica instance
- Instance가 하나만 있을 경우, primary endpoint = reader endpoint
- 쓰기 시도 시, 오류 발생 (위의 경우 제외)
- replica 세트로 Amazon DocumentDB에 연결
- 이하 모든 설정들은 replica 세트 모드에 해당되는 내용
- Cluster endpoint -> primary instance
Instance
- Instance: cloud의 격리된 DB 환경
- Instance에는 여러 개의 DB가 포함될 수 있음
- DocumentDB instance는 VPC에서만 실행
- Cluster 생성한 다음, instance를 생성
Storage
- DocumentDB 데이터는 SSD 단일 가상 볼륨인 cluster volume에 저장
- 3개의 가용 영역에 6개의 데이터 사본을 복제하여 높은 가용성과 내구성을 제공
- 데이터를 여러 instance에 복제하지 않음으로서 데이터의 내구성을 유지
Write Durability
- 내구성은 컴퓨팅과 분리된 스토리지 계층에서 처리되기 때문에, 단일 instance cluster와 복수 instance cluster의 내구성은 동일함
- Cluster에 대한 쓰기는 단일 문서 내에서 원자성을 가짐
Read Isolation
- Instance에서 읽기 시, 쿼리가 실행되기 전에 내구성이 있는 데이터만 반환
- Dirty read 불가능
High Availability
- Cluster에 replica이 없는 경우, 장애가 발생하는 동안 primary instance가 생성
그러나, 느리기 때문에 replica을 장애 조치 대상으로 생성하는 것을 권장 - 장애 조치 대상 replica
- Primary instance와 동일한 instance class에 속해야함
- Primary instance와 다른 가용 영역에 프로비저닝되어야 함
- Amazon DocumentDB 클러스터 내결함성에 대한 이해 참고
Scaling Reads
- 애플리케이션에 읽기 용량이 더 필요하거나 줄어들면 cluster에 replica를 추가/제거할 수 있음 (보통 10분 미만)
- Amazon DocumentDB 읽기 환경설정 참고
- Replica set 권장 시나리오
- Primary instance CPU 사용률(
CPUUtilization) ≈ 100% - Buffer cache hit ratio(
BufferCacheHitRatio) ≈ 0% - 개별 instance의 connection / cursor 한계에 도달(
DatabaseConnections)
- Primary instance CPU 사용률(
Reference
PREVIOUSEtc