이 프로젝트에서는 간단한 구조에서부터 다양한 한계점들을 해결해나가며 점점 성능이 높아지는 RAG 에이전트를 구현해보고자 합니다.
차근차근 그 과정들을 소개하려고 하는데요, 먼저 LLM의 한계점을 생각해보면서 RAG가 무엇인지 알아봅시다.
LLM은 굉장히 많은 것들을 알고 있지만 지식의 한계는 학습된 데이터의 한계(knowledge cut-off)에 해당합니다.
가령, “사내 인사변동에 대해 알려줘!”, “실시간 인기 검색어를 알려줘!” 와 같이 공개되지 않은 데이터 혹은 실시간 데이터에 대한 지식을 가지고 있지 않죠.
이처럼 학습되지 않은 데이터에 대하여 질문을 받았을 때, LLM은 사용자가 원하는 답변을 주지 못합니다.
심지어 그럴싸한 거짓말을 하는 환각(hallucination) 현상이 발생하기도 하죠.
이러한 외부 데이터에 대한 접근과 환각과 같은 LLM의 태생적인 한계점을 극복하기 위해 나온 기술이 바로 RAG 입니다.
RAG(Retrieval Augmented Generation)
RAG is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs’ generative process. \
https://research.ibm.com/blog/retrieval-augmented-generation-RAG
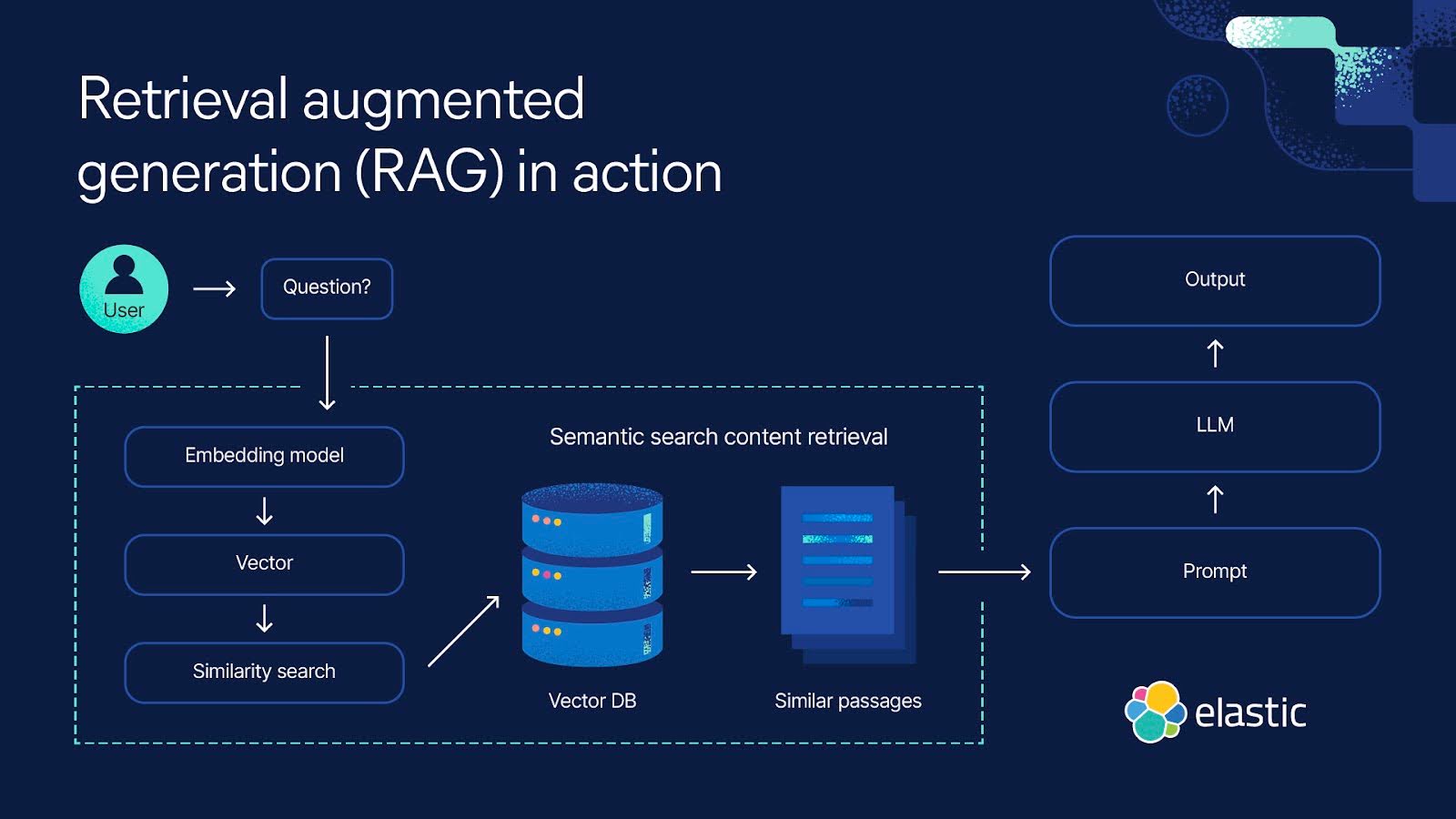 Image from https://www.elastic.co/kr/what-is/retrieval-augmented-generation
Image from https://www.elastic.co/kr/what-is/retrieval-augmented-generation
다양한 데이터 소스로부터 사용자의 요청과 관련된 문서를 검색하고, 이를 기반으로 LLM을 이용하여 답변을 생성하는 기술을 RAG(Retrieval Augmented Generation)라 합니다.
이번 프로젝트에서 집중할 데이터 소스는 웹 데이터입니다. 가장 기본적이지만 필수적이고, 방대하며 효과적이죠!
 Image from pixabay
Image from pixabay
코드의 기본적인 구조는 다음과 같습니다.
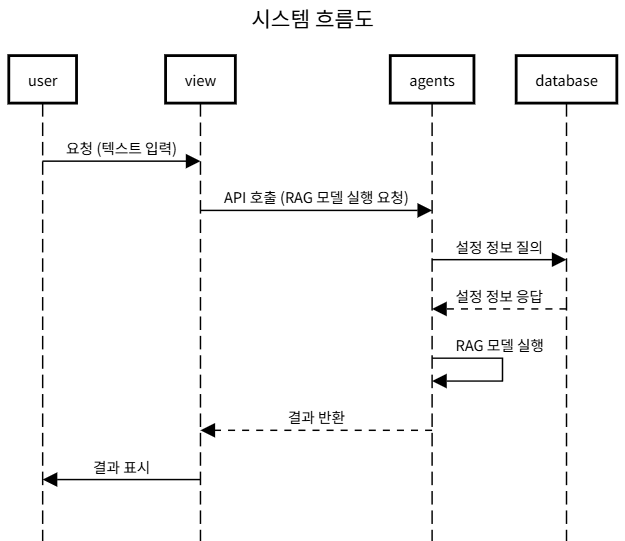
RAG 에이전트(agents)와 관련된 소스코드는 https://github.com/alchemine/agents-grocery 이곳에 공개되어 있고 각 포스팅에 해당하는 코드는 Tag를 통해 확인하실 수 있습니다.
자 그럼 바로 시작하시죠!