Summary \
- 한계점 1. 검색이 필요하지 않은 발화의 경우, 의미없는 검색결과를 기반으로 답변을 생성 \
- 해결빙안: LLM을 활용하여 사용자의 요청을 처리하기 위해, 검색이 필요한지 체크하는 로직 추가 \
- 고도화 1: 검색 필요 여부 판단 정확도를 높이기 위해, 검색 결과를 포함하여 해당 검색 결과의 필요 여부를 판단하도록 로직 변경 \
- 고도화 2: 추가 LLM으로 인한 소요시간 증가를 완화시키기 위해, SLM 혹은 finetuned encoder 사용
가장 기본적인 RAG의 구조는 사용자의 질문과 관련된 문서를 프롬프트에 넣고 답변을 생성하는 방식입니다.
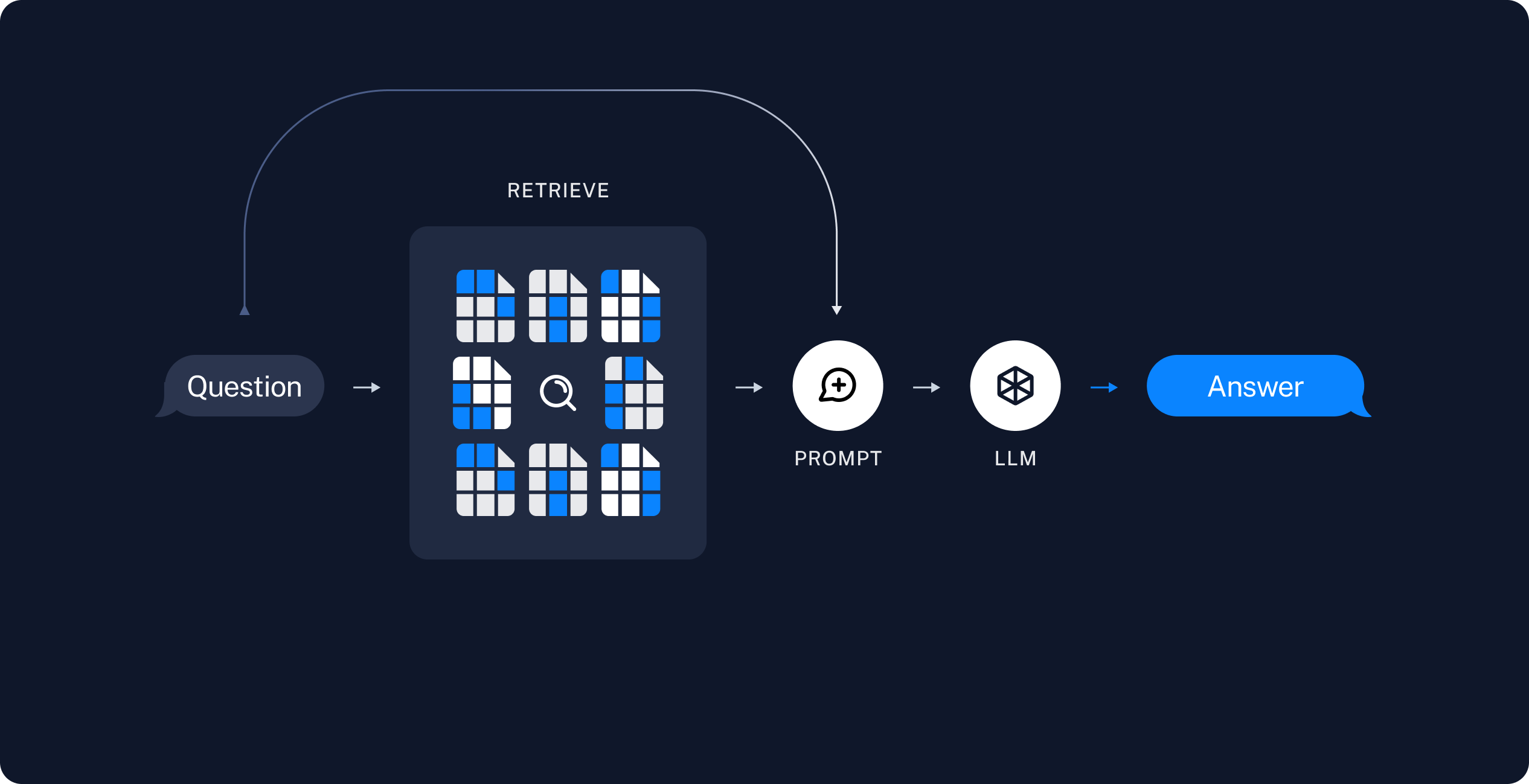 Image from https://python.langchain.com/docs/tutorials/rag/
Image from https://python.langchain.com/docs/tutorials/rag/
이러한 기본 구조에선, “안녕”과 같이 검색이 필요하지 않은 사용자의 발화가 들어왔을 때도 검색을 수행하여 오히려 답변의 품질이 떨어지는 문제가 발생합니다.
이를 해결하기 위해, 사용자의 발화/요청을 처리하기 위해 검색이 필요한지 검사하는 로직이 사용될 수 있습니다.
해당 로직을 LangGraph를 활용하여 구현하면 다음과 같은 그래프를 볼 수 있습니다.
- https://python.langchain.com/docs/tutorials/qa_chat_history/
- https://github.com/langchain-ai/retrieval-agent-template

위의 구현에서 검색 도구의 필요 여부를 다음과 같은 코드로 구현하였습니다.
# Step 1: Generate an AIMessage that may include a tool-call to be sent.
def query_or_respond(state: MessagesState):
"""Generate tool call for retrieval or respond."""
llm_with_tools = llm.bind_tools([retrieve])
response = llm_with_tools.invoke(state["messages"])
# MessagesState appends messages to state instead of overwriting
return {"messages": [response]}
프롬프트 없이 간단히 대화기록(messages)를 입력받아 검색이 필요하다고 판단될 경우 retrieve 도구를 호출하고, 그렇지 않으면 답변을 생성하는 로직입니다.
충분해보이지만, 다음과 같은 예제에선 잘못된 결과 혹은 예상치 못한 결과가 나타날 수 있습니다.
Human: LangChain에서 LLM을 작동시킬 때 사용하는 메서드가 뭐야?
AI(오답): `__call__()` 을 사용합니다.
AI(정답): `invoke()` 를 사용합니다.
__call__() 메서드는 과거에 사용되었던 메서드로 현재는 deprecated 되어 사용이 권장되지 않습니다.
하지만, 과거 데이터를 학습한 LLM은 이를 판단하는 로직이 명시적으로는 없기 때문에 종종 이러한 바람직하지 못한 답변을 내놓곤 합니다.
즉, 프롬프트와 weight knowledge만으로는 검색 필요 여부를 정확히 예측하기에 어려움이 있습니다. 특히, 예제와 같이 최신 데이터와 관련된 경우 더더욱 컨트롤하기 어려워집니다.
이러한 문제를 근본적으로 해결하기 위해선, 우선 사용자 발화와 관련된 외부 데이터를 가져오고 이를 바탕으로 사용자의 발화를 심도깊게 분석해야 합니다.
위의 코드를 변경하자면, 다음과 같이 순차적으로 retrieve, llm 모델을 호출할 수 있습니다.
# Step 1: Generate an AIMessage that may include a tool-call to be sent.
def query_or_respond(state: MessagesState):
"""Generate tool call for retrieval or respond."""
prompt = ...
state["contexts"] = retrieve.invoke(state["messages"])
response = prompt | llm.invoke(state["messages"], state["contexts"])
# MessagesState appends messages to state instead of overwriting
return {"messages": [response]}
한편, LLM 호출이 추가되기 때문에 답변에 소요되는 시간은 증가하게 됩니다.
서비스적인 측면에서 매우 기분이 좋지 않은 일이므로, 작업의 복잡도와 소요시간의 trade-off를 고려하여 SLM 혹은 finetuned encoder를 사용하는 방편도 고려해볼 수 있습니다.
가령, 답변 생성은 gpt-5, 쿼리 분석은 gpt-5-mini를 사용하는 것도 좋은 시작점이 될 수 있습니다.