A Neural Network Playground를 굴려본 결과에 대한 글입니다.
1. Nerual network is stacking(hierarchical) model
1.1 # hidden layers = 1
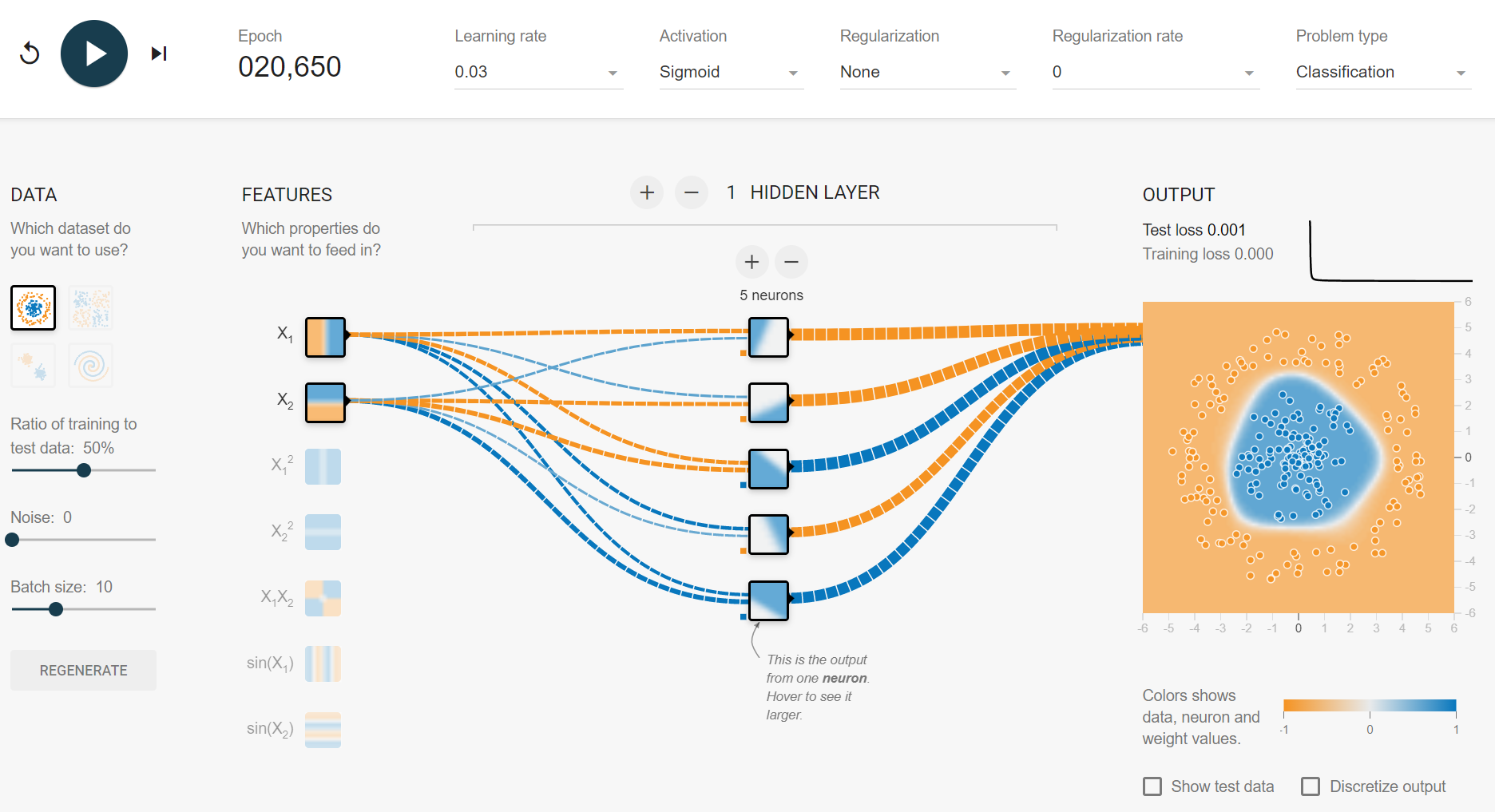
학습된 1st hidden layer의 1st node의 출력값은 다음과 같다. $H_{1,1}(X_1, X_2) = \sigma (-1.5 X_1 + 0.62 X_2 - 3.2)$
- 1st hidden layer의 각 node들은
logistic regressionmodel이 된다.
그리고 최종 출력값은 학습된 5개의 node에 해당되는 model들의 stacking(blending) model에 해당한다. - Blender(output node)와 learner(hidden node)들을 학습하는 데 분리된 데이터를 사용하는 일반적인 stacking 학습 algorithm과 달리 모든 layer(learner)들을 gradient backpropagation(reverse-mode autodiff)로 학습시킨다는 점에서 차이가 있다.(DNN을 효과적으로 학습시키기 위한 여러가지 방법들은 여기를 참고)
- 1st hidden layer의 node들은 input($X_1, X_2$)에 대한 linear decision boundary를 가진다.
1.2 # hidden layers = 2
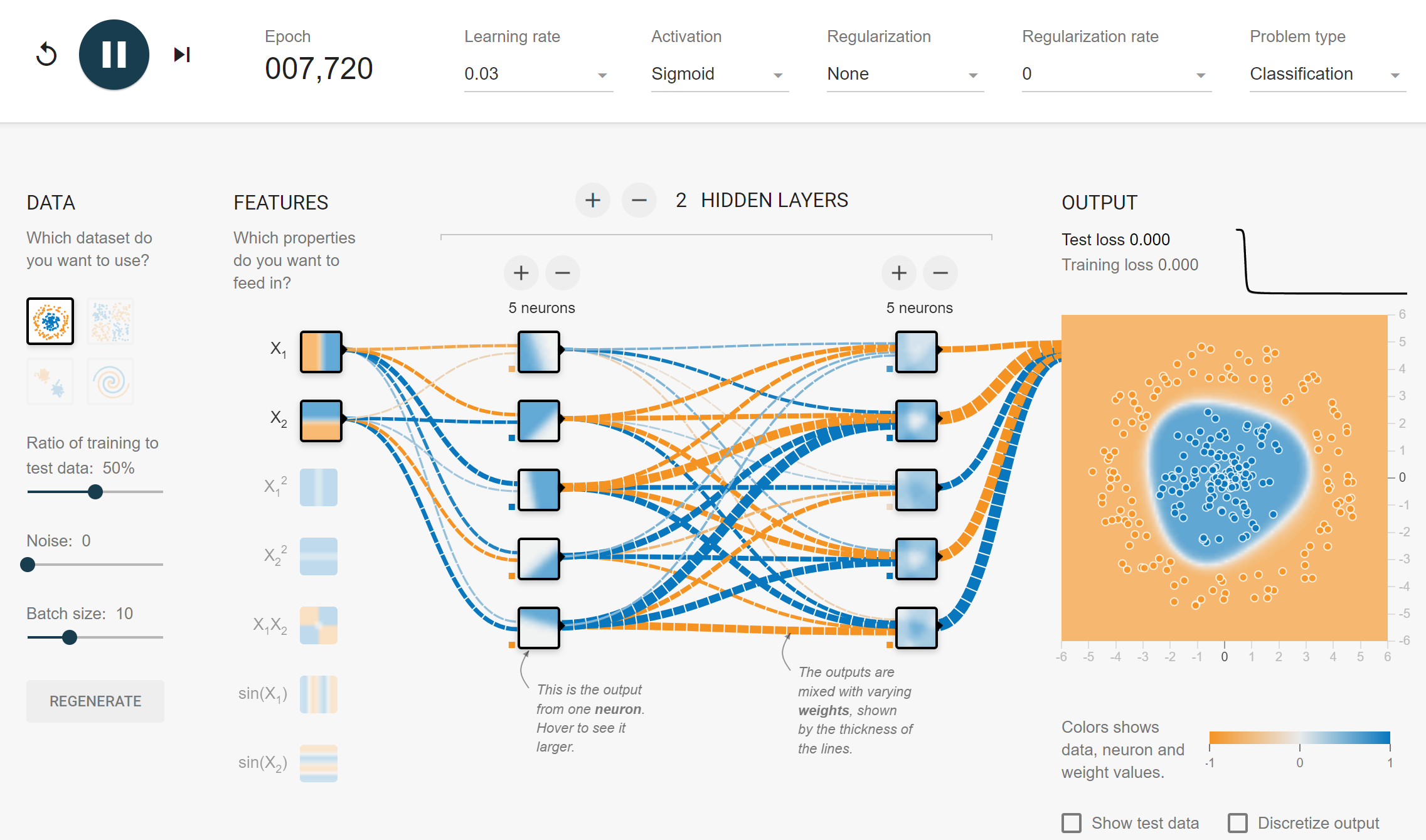
학습된 2nd hidden layer의 1st node의 출력값은 다음과 같다. $H_{2,1}(H_{1,1}, H_{1,2}, …, H_{1,5}) = \sigma (0.45 H_{1,1} - 1.4 H_{1,2} - 1.3 H_{1,3} + 0.41 H_{1,4} + 0.4 H_{1,5} + 0.7)$
- $n$-th hidden layer($n>1$)의 node들은 ($n$-1)-th hidden layer에서 생성된 model들의 stacking model이다.
- $n$-th hidden layer($n>1$)의 node들은 input($X_1, X_2$)에 대한 non-linear decision boundary를 가진다.
1.3 # hidden layers > 2
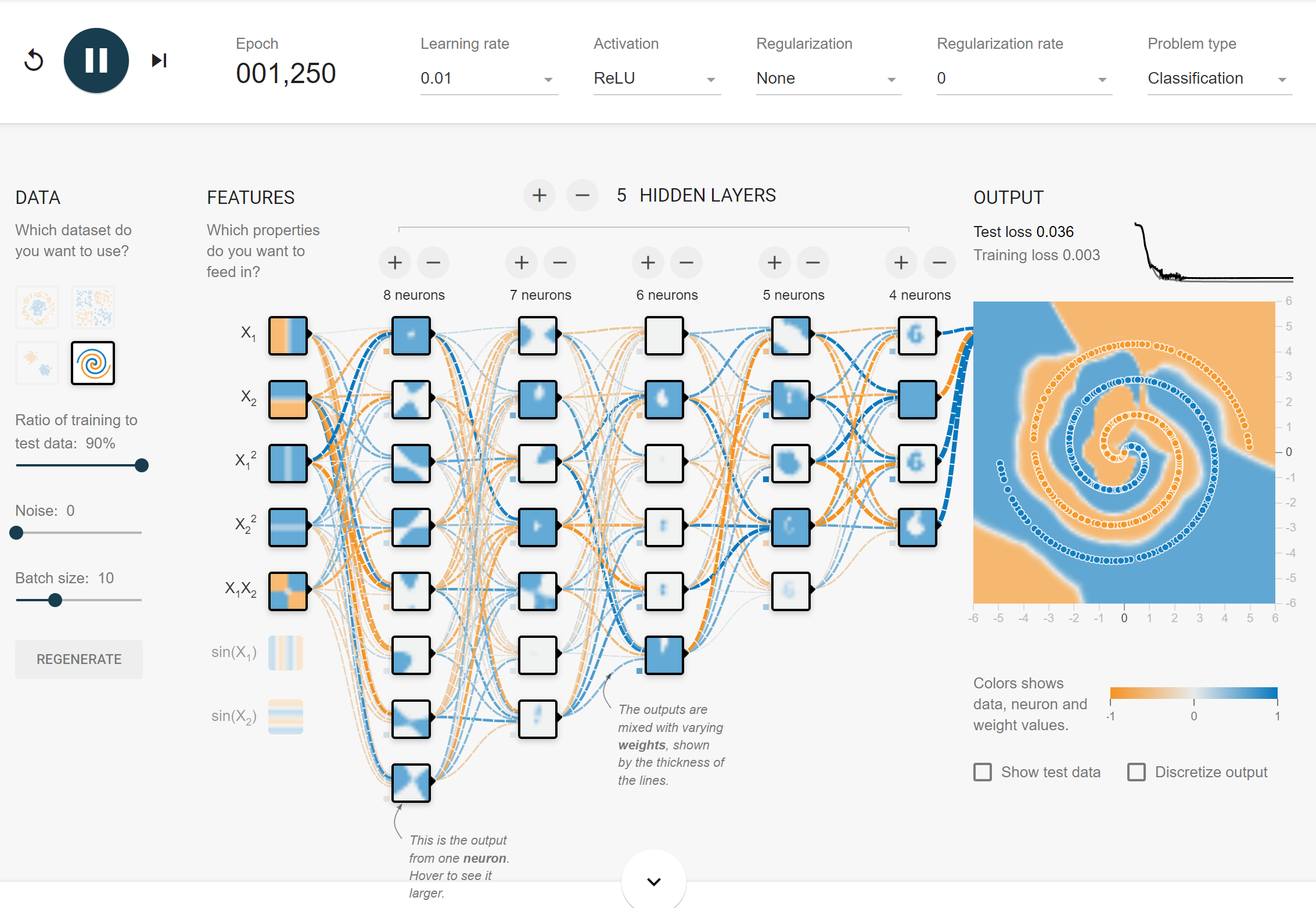
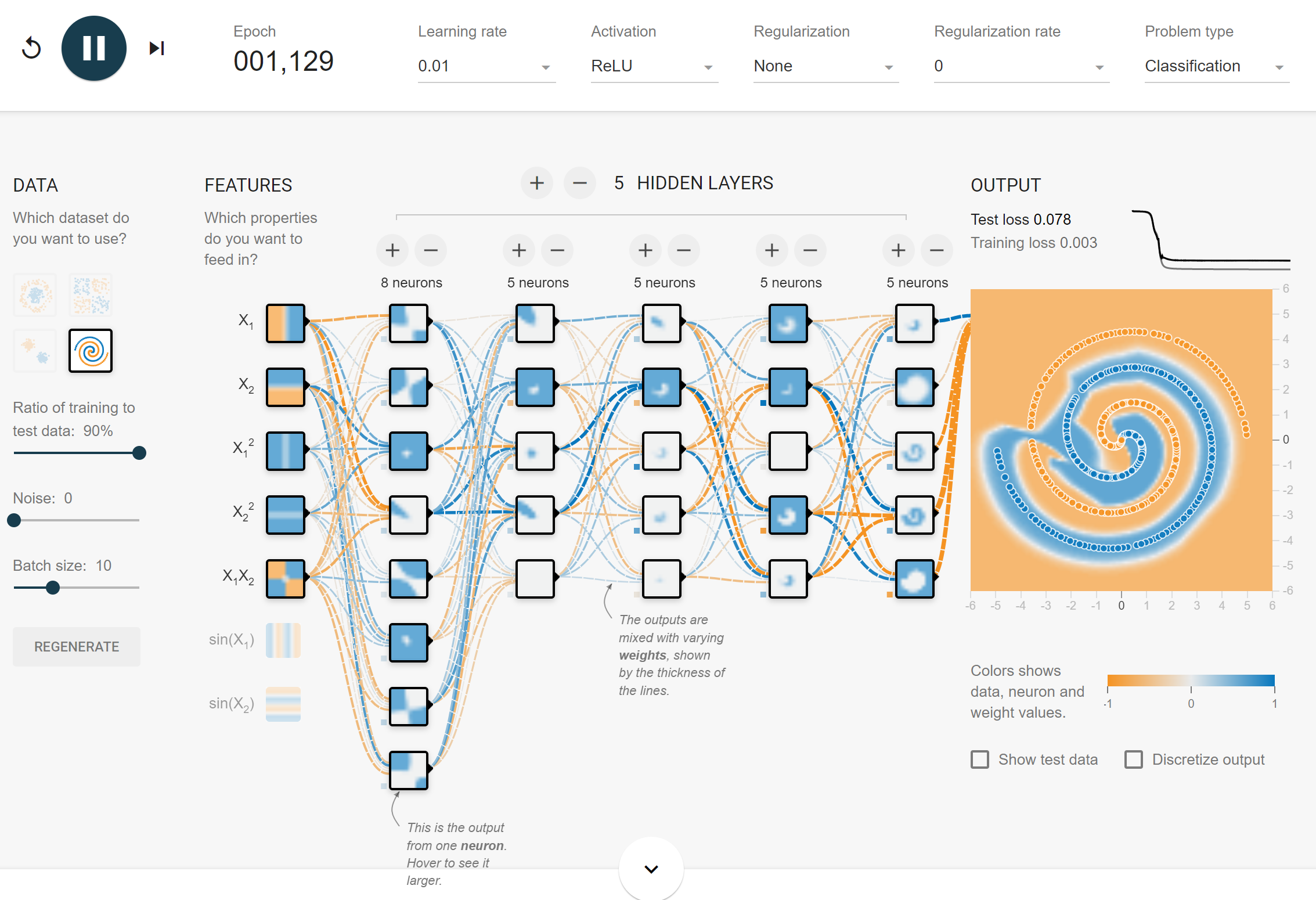
- 깊은 layer의 node일수록 복잡한 model을 학습한다.
- Dying node들이 종종 보이는데 이들은 학습의 효율성을 떨어뜨린다.
→LeakyReLU등을 통해 이를 줄일 수 있다.
2. Batch size
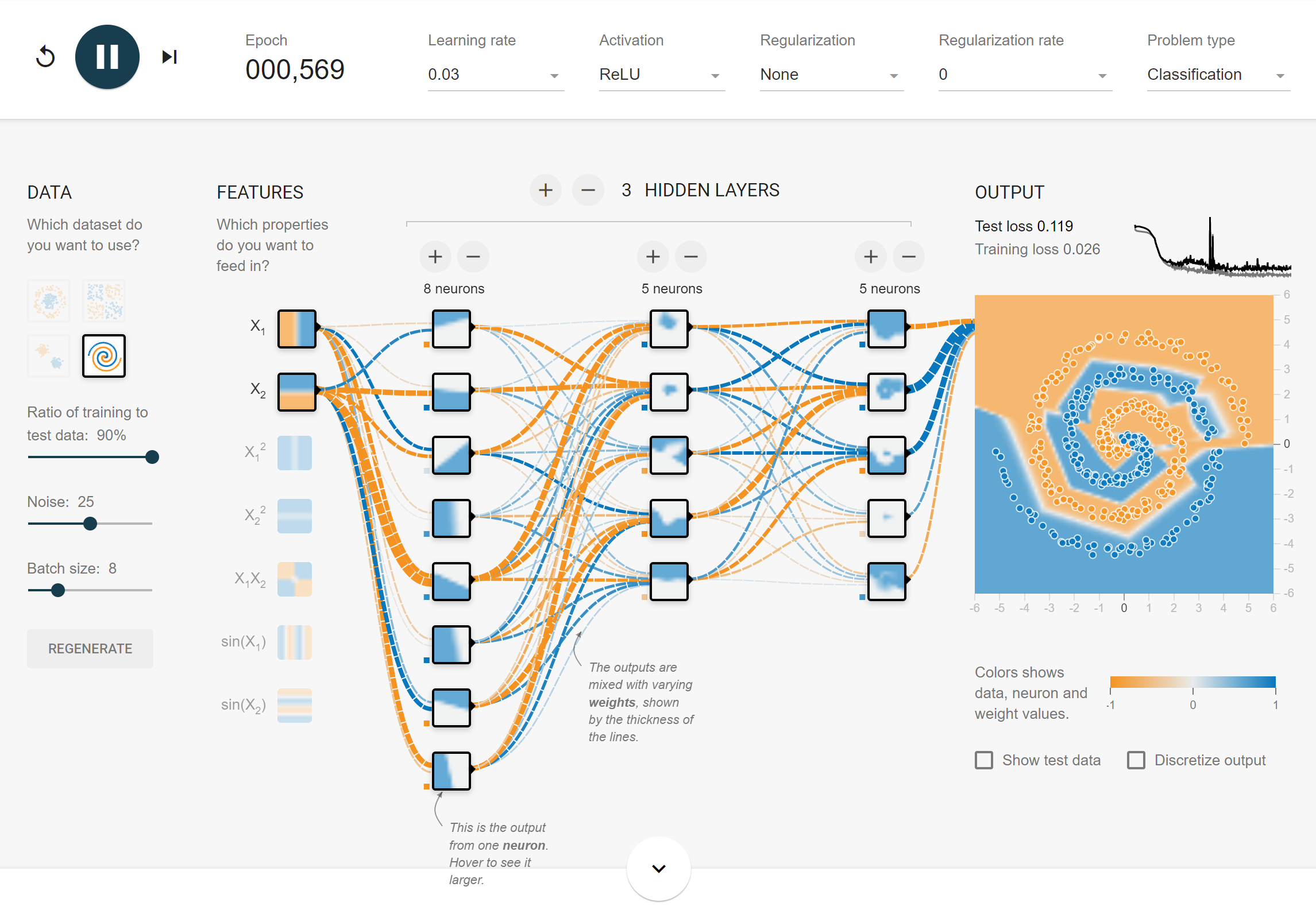
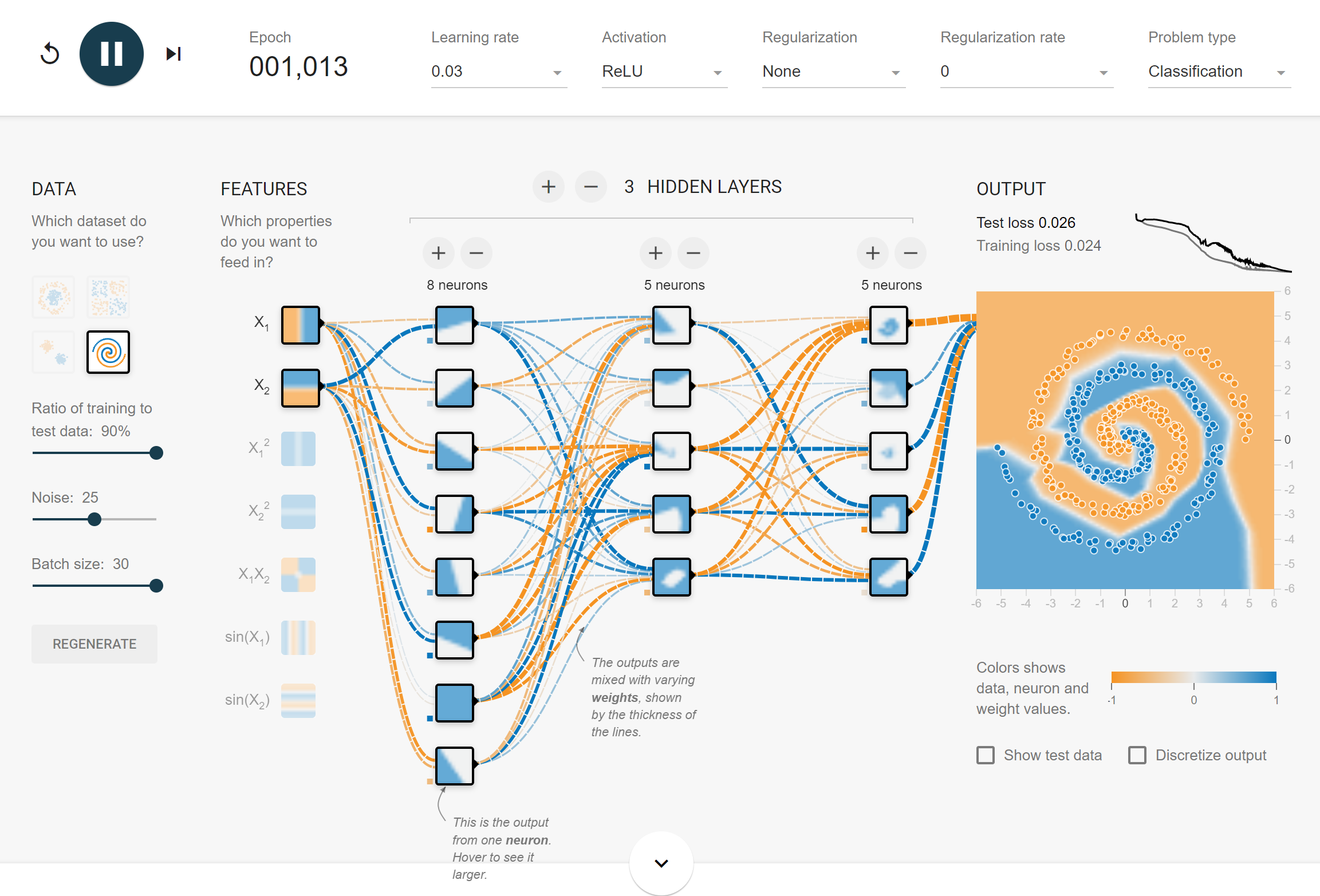
작은 batch size로 학습할 시,
- 수렴이 굉장히 빠르다.
- 일반화 성능이 높다.
- 중간에 loss가 튀는 경우가 많다.
PREVIOUSEtc