Remarks
본 포스팅은 Hands-On Machine Learning with Scikit-Learn & TensorFlow (Auérlien Géron, 박해선(역), 한빛미디어) 를 참고하여 작성되었습니다.
1. Problem
Vanishing Gradient
Neural network의 하위층으로 갈수록 역전파되는 gradient의 크기가 점점 작아지는 현상
Exploding Gradient
Neural network의 하위층으로 갈수록 역전파되는 gradient의 크기가 점점 커지는 현상
기존(2010년 이전)에 사용했던 sigmoid activation function과 표준정규분포($N(0, 1)$)로 weight를 초기화하는 방법은 각 layer마다 gradient의 크기를 불안정하게 만들었다.
이는 각 layer의 학습 속도를 다르게 하기 때문에 DNN의 학습을 어렵게 만들었다.
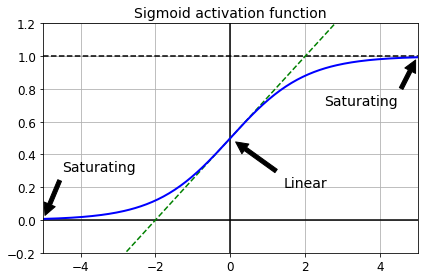
- Exploding Variance
각 layer에서, output의 분산 > input의 분산 - Gradient of Sigmoid function
Sigmoid함수는 input/output이 커질수록 gradient의 크기가 0으로 수렴 - Vanishing Gradient
Gradient가 layer를 거치며 역전파될 때, 0에 가까운 gradient가 곱해져(chain rule) 사라짐
2. Solutions
2.1 Weight initialization
- Preserved Variance
(Forward) 각 layer에서, output의 분산 ≈ input의 분산
(Backward) 각 layer에서, layer 통과 이전 gradient의 분산 ≈ layer 통과 이후 gradient의 분산
이하 code는 Initializers - Keras Documentation 참고
str 값으로 간단히 사용가능한 kernel initializer는 다음과 같다.
from tensorflow import keras
[name for name in dir(keras.initializers) if not name.startswith("_")]
['Constant', 'GlorotNormal', 'GlorotUniform', 'HeNormal', 'HeUniform', 'Identity', 'Initializer', 'LecunNormal', 'LecunUniform', 'Ones', 'Orthogonal', 'RandomNormal', 'RandomUniform', 'TruncatedNormal', 'VarianceScaling', 'Zeros', 'constant', 'deserialize', 'get', 'glorot_normal', 'glorot_uniform', 'he_normal', 'he_uniform', 'identity', 'lecun_normal', 'lecun_uniform', 'ones', 'orthogonal', 'random_normal', 'random_uniform', 'serialize', 'truncated_normal', 'variance_scaling', 'zeros']
2.1.1 Xavier(Glorot) initialization
- Normal distribution version: $W_{init} \sim N(0, \frac{1}{fan_{avg}})$
- Uniform distribution version: $W_{init} \sim U(-\sqrt{\frac{3}{fan_{avg}}}, \sqrt{\frac{3}{fan_{avg}}})$
- $fan_{avg} = (fan_{in} + fan_{out})/2$
- Sigmoid 형태의 activation function과 사용(
sigmoid,softmax,tanh등)
keras.layers.Dense(kernel_initializer='glorot_normal', activation='softmax')
keras.layers.Dense(kernel_initializer='glorot_uniform', ..) # default kernel initializer
2.1.2 He initialization
- Normal distribution version: $W_{init} \sim N(0, \frac{2}{fan_{in}})$
- Uniform distribution version: $W_{init} \sim U(-\sqrt{\frac{6}{fan_{in}}}, \sqrt{\frac{6}{fan_{in}}})$
ReLU계열 activation function과 사용(ReLU,LeakyReLU,ELU등)
keras.layers.Dense(kernel_initializer='he_normal', activation='elu')
keras.layers.Dense(kernel_initializer='he_uniform', ..)
2.1.3 LeCun initialization
- Normal distribution version: $W_{init} \sim N(0, \frac{1}{fan_{in}})$
- Uniform distribution version: $W_{init} \sim U(-\frac{3}{fan_{in}}, \frac{3}{fan_{in}})$
SELUactivation function과 사용(normal distribution version)
keras.layers.Dense(kernel_initializer='lecun_normal', activation='selu', ..)
keras.layers.Dense(kernel_initializer='lecun_uniform', ..)
2.2 Activation function
Output이 특정 양숫값으로 수렴하지 않는다는 장점을 기반으로 하는 ReLU기반 activation function들이 주로 사용된다.
다양한 변종들 중 일반적으로 SELU(FC, CNN) > ELU(RNN) > LeakyReLU가 주로 사용됨
이하 code는 Activations - Keras Documentation 참고
str 값으로 간단히 사용가능한 activation function은 다음과 같다.
from tensorflow import keras
[name for name in dir(keras.activations) if not name.startswith("_")]
['deserialize', 'elu', 'exponential', 'gelu', 'get', 'hard_sigmoid', 'linear', 'relu', 'selu', 'serialize', 'sigmoid', 'softmax', 'softplus', 'softsign', 'swish', 'tanh']
추가로 Leaky ReLU, PReLU 등의 activation function도 사용가능하다.
자세한 것은 Advanced Activations - Keras Documentation를 참고
2.2.1 LeakyReLU
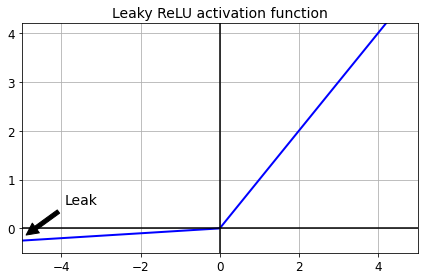 \(\text{leaky relu}(z) =
\begin{cases}
z & \quad \text{if } z > 0 \\
\alpha z & \quad \text{if } z \leq 0
\end{cases}\)
\(\text{leaky relu}(z) =
\begin{cases}
z & \quad \text{if } z > 0 \\
\alpha z & \quad \text{if } z \leq 0
\end{cases}\)
$\alpha=0.3$ 정도의 값을 주로 사용
- 음수의 input에 대해서 0의 값만을 출력하는 Dying ReLU 문제를 해결하기 위해 약간의 leaking($\alpha$)을 추가
- 일반적으로
ReLU보다 성능이 좋고 빠르다.
keras.layers.Dense(activation='leaky_relu', kernel_initializer='he_normal')
keras.layers.Dense(activation=keras.layers.LeakyReLU(alpha=0.3), kernel_initializer='he_normal') # default
2.2.2 ELU
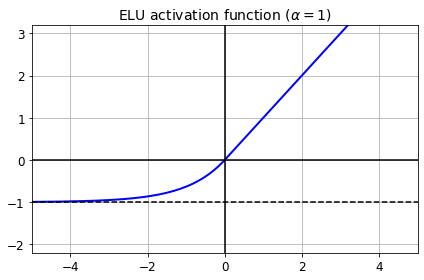 \(\text{elu}(z) =
\begin{cases}
\alpha (e^z -1) & \quad \text{if } z \leq 0 \\
z & \quad \text{if } z > 0
\end{cases}\)
\(\text{elu}(z) =
\begin{cases}
\alpha (e^z -1) & \quad \text{if } z \leq 0 \\
z & \quad \text{if } z > 0
\end{cases}\)
$\alpha=1$을 주로 사용($\alpha \neq1$ 이면 $z=0$에서 미분불가)
- 일반적으로
ReLU변종들 중 가장 성능이 좋고, 수렴이 빠르다. - 테스트 시, 계산이 느리다.
keras.layers.Dense(activation='elu', kernel_initializer='he_normal')
keras.layers.Dense(activation=keras.layers.ELU(alpha=1), kernel_initializer='he_normal') # default
2.2.3 SELU(Scaled ELU)
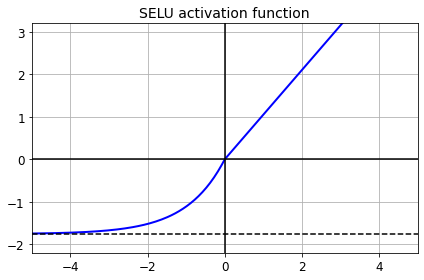 \(\text{selu}(z) = \lambda
\begin{cases}
\alpha (e^z -1) & \quad \text{if } z \leq 0 \\
z & \quad \text{if } z > 0
\end{cases}\)
\(\text{selu}(z) = \lambda
\begin{cases}
\alpha (e^z -1) & \quad \text{if } z \leq 0 \\
z & \quad \text{if } z > 0
\end{cases}\)
$\lambda$, $\alpha$는 상수이다.
값은 paper-expression(14), tf.keras.activations.selu를 참고
- 자기 정규화(self-normalize)
다음의 조건을 만족하면, 훈련 시, 모든 layer의 output의 평균=0, 분산=1 아 된다.- Every layer:
SELUactivation function - Every layer: Fully connected (skip connection: 사용 X)
- Weight initialization:
LeCuninitialization - Input features: Standardized
- Batch normalization: 사용 X
- Dropout 대신, AlphaDropout 사용(input의 mean, variance를 유지)
- Every layer:
models = keras.models.Sequential([
keras.layers.BatchNormalization()
keras.layers.Dense(activation='selu', kernel_initializer='lecun_normal'),
keras.layers.AlphaDropout(0.2),
keras.layers.Dense(activation=keras.activations.selu, kernel_initializer='lecun_normal'),
keras.layers.AlphaDropout(0.2),
...
])
2.3 Batch Normalization
He initialization와 ELU를 사용한다해도, 학습 도중에 vanishing, exploding gradient 문제가 발생하지 않는다는 보장을 할 수 없다.
Batch normalization은 layer의 output을 간접적으로 정규화하기 때문에 학습 도중에도 vanishing, exploding gradient 문제가 발생하는 것을 방지할 수 있다.
- Position
- Input layer 직후
이 경우, input의 standardization이 불필요 - CONV/FC → BatchNorm → Activation → Dropout
최근엔 주로 이런 순서로 사용한다고 한다. (Ordering of batch normalization and dropout? 참고)- Kernel에서 bias 제거(
use_bias=False)
- Kernel에서 bias 제거(
- Dropout과 함께 사용할 때 오히려 성능이 떨어지는 경우도 있다
Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift 참고
- Input layer 직후
- Gradient 문제를 해결하는 가장 대표적인 방법이지만, RNN에서는 사용되지 않음(?)
- Regularization 효과가 미약하기 때문에 dropout을 함께 사용하는 것이 좋음
- 학습 시와 예측 시 수행하는 계산이 다르기 때문에 주의(MC dropout)
from tensorflow.keras.layers import Dense, BatchNormalization, Activation, Dropout
model_bn_after_activation = keras.models.Sequential([
BatchNormalization(input_shape=[784]),
Dense(100, activation='elu', kernel_initializer='he_normal'),
BatchNormalization(),
Dropout(0.2),
Dense(100, activation='elu', kernel_initializer='he_normal'),
BatchNormalization(),
Dropout(0.2),
Dense(10, activation='softmax'), # default kernel_initializer: 'glorot_uniform'
])
model_bn_before_activation = keras.models.Sequential([
BatchNormalization(input_shape=[784]),
Dense(100, kernel_initializer='he_normal', use_bias=False),
BatchNormalization(),
Activation('elu'),
Dropout(0.2),
Dense(100, kernel_initializer='he_normal', use_bias=False),
BatchNormalization(),
Activation('elu'),
Dropout(0.2),
Dense(10, activation='softmax'), # default kernel_initializer: 'glorot_uniform'
])
2.4 Gradient Clipping
Exploding gradient를 막기위해 gradient가 임계값을 넘어서지 못하게 잘라낼 수 있다.
Batch normalization을 사용하기 어려운 RNN에서 주로 사용된다.
optimizer = keras.optimizers.SGD(clipvalue=1.0)
optimizer = keras.optimizers.SGD(clipnorm=1.0)