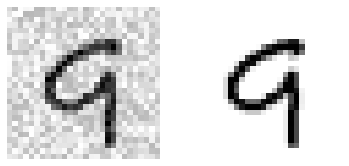Remarks
본 포스팅은 Hands-On Machine Learning with Scikit-Learn & TensorFlow (Auérlien Géron, 박해선(역), 한빛미디어) 를 기반으로 작성되었습니다.
Import libraries and functions
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plot
%matplotlib inline
p = lambda *x: print(*x)
# plotting functions
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap=matplotlib.cm.binary)
plt.axis('off')
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = matplotlib.cm.binary, **options)
plt.axis("off")
I. MNIST
1
2
3
4
5
6
7
8
9
10
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
# Load MNIST
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist['data'], mnist['target'].astype(np.int)
# Generate train, test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/7, stratify=y, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
II. Training a Binary Classifier
1
2
3
4
5
6
7
8
9
from sklearn.linear_model import SGDClassifier
# Train 5 or not binary classifier
y_train_5, y_test_5 = (y_train == 5), (y_test == 5)
some_digit = 42
sgd_clf = SGDClassifier(max_iter=5, random_state=42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([some_digit])
III. Performance Measures
1. Measuring Accuracy Using Cross-Validation
1
2
3
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring='accuracy')
2. Confusion Matrix
1
2
3
4
5
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
confusion_matrix(y_train_5, y_train_pred)
3. Precision and Recall
자세한 설명은 https://alchemine.github.io/2019/07/17/confusion-matrix.html 참조
1
2
3
4
5
from sklearn.metrics import precision_score, recall_score, f1_score
precision_score(y_train_5, y_train_pred)
recall_score(y_train_5, y_train_pred)
f1_score(y_train_5, y_train_pred)
4. Precision/Recall TradeOff
1
2
# predict() is equal to 'decision_funcion() > threshold=0'
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method='decision_function')
5. The ROC Curve
PR Curve와 ROC Curve는 https://alchemine.github.io/2019/07/18/curves.html을 참조
IV. Multiclass Classification
1
2
3
4
# SGDClassifier uses OvA strategy when performed in multiclass classification
sgd_clf.fit(X_train, y_train)
some_digit_scores = sgd_clf.decision_function([some_digit])
sgd_clf.classes_
OvA, OvO에 대한 설명은 https://alchemine.github.io/2019/07/13/ovaovr.html 참조
V. Error Analysis
https://alchemine.github.io/2019/07/18/error_analysis.html를 참조
VI. Multilabel classification
여러 개의 이진 레이블을 출력하는 분류 시스템을 다중 레이블 분류 (multilabel classification) 시스템이라고 합니다.
KNeighborsClassifier, DecisionTree, RandomForest, OneVsRestClassifier 등의 모델에서 다중 레이블 분류를 지원합니다.
1
2
3
4
5
6
7
8
9
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
knn_clf.predict([some_digit])
다중 레이블 분류기를 평가할 때 다음과 같이 레이블 클래스의 지지도 (support, target 레이블에 속한 sample 수)를 가중치로 사용한 $F_1$ score를 사용할 수 있습니다.
1
2
3
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3, n_jobs=-1)
f1_score(y_multilabel, y_train_knn_pred, average='weighted')
# 모든 레이블의 가중치가 동일하게 하고 싶다면 average='macro'
VII. Multioutput Classification
다중 출력 다중 클래스 분류 (multioutput-multiclass classification) 혹은 다중 출력 분류는 다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화한 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
noise_train = np.random.randint(0, 100, (len(X_train), 784))
noise_test = np.random.randint(0, 100, (len(X_test), 784))
X_train_mod = X_train + noise_train
X_test_mod = X_test + noise_test
y_train_mod, y_test_mod = X_train, X_test
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
plot_digit(X_test_mod[some_index])
plot_digit(y_test_mod[some_index])
plot_digit(clean_digit)